前后台进程、孤儿进程和daemon类进程的父子关系
前后台进程、孤儿进程和daemon类进程的父子关系
前台进程、后台进程和进程父子关系
前台进程是占用当前终端的进程,只有该进程执行完成或被终止之后,才会释放终端并将终端交还给shell进程。
例如:
$ sleep 30
执行该命令后,将创建sleep进程,sleep进程是当前bash进程(假如当前的shell为bash)的子进程:
$ pstree -p | grep sleep
|-bash(31207)---sleep(31800)
在30秒内,sleep进程将占用终端,所以此时的sleep称为前台进程。当睡眠30秒之后,前台进程sleep退出,终端控制权交还给当前shell进程,shell进程可继续向下运行命令或等待用户输入新命令。
如果给命令加上一个&符号,该命令将在后台运行。
$ sleep 30 &
此时,sleep仍然是当前bash的子进程,但是它不会占用终端,而是在后台默默地运行,并且在30秒之后默默的退出。
如果是在一个子Shell环境中运行一个前台进程呢?例如:
$ ( sleep 30 )
执行这个命令时,小括号会开启一个子Shell环境,这相当于当前的bash进程隔离了一个bash运行时环境。sleep进程将在这个新的子Shell环境中运行,sleep仍然是当前bash的子进程。由于它会占用当前的终端,所以它是前台进程。
30秒之后,sleep进程退出,它将释放终端,与此同时,子Shell环境也会随着sleep进程的终止而关闭。
如果不了解子Shell,也可以通过shell脚本来理解,或程序内部使用system()来理解,它们都是提供了一种执行外部命令的运行环境。
例如bash -c 'sleep 30',sleep进程将在该bash进程提供的环境下运行,它是该bash进程的子进程。
再例如shell脚本:
#!/bin/bash
sleep 30
sleep将在这个bash脚本进程提供的环境下运行,它是该脚本进程的子进程。
再例如Perl脚本:
#!/bin/perl
system('sleep 30')
sleep将在这个Perl脚本进程提供的环境下运行。
需注意,编程语言(如Perl)可能提供多种调用外部程序的方式,比如system('sleep 30')和system('sleep',30),这两种方式有区别:

举几个例子帮助理解,假设有Perl脚本a.pl,其内三行内容为:
system('sleep',30); #(1)
system('sleep 30 ; echo hhh'); #(2)
system('sleep 30'); #(3)
对于(1),命令和参数分开,perl将直接调用sleep程序,这时的sleep进程是perl进程a.pl的子进程,且不支持使用管道|、重定向> < >>、&&等等属于Shell支持的符号。
$ pstree -p | grep sleep
| `-bash(31696)---a.pl(32707)---sleep(32708)
对于(2),perl将调用sh,并将参数sleep 30; echo hhh作为sh -c的参数运行,等价于sh -c 'sleep 30; echo hhh',所以sh进程将是perl进程的子进程,sleep进程将是sh进程的子进程。
$ pstree -p | grep sleep
| `-bash(31696)---a.pl(32747)---sh(32748)---sleep(32749)
另外需要注意的是,(2)中的命令是多条命令,而不是简简单单的单条命令,因为识别多条命令并运行它们的能力是Shell解析提供的,所以上面涉及了Shell的解析过程。由于会调用sh命令,所以允许命令中使用Shell特殊符号,比如管道符号。
对于(3),perl本该调用sh,并将sleep 30作为sh -c的参数运行。但此处是一个简单命令,不涉及任何Shell解析过程,所以会优化为等价于system('sleep', 30)的方式,即不再调用sh,而是直接调用sleep,也即sleep不再是sh的子进程,而是perl进程的子进程:
$ pstree -p | grep sleep
| `-bash(31696)---a.pl(32798)---sleep(32799)
其实子shell中运行命令和system()运行命令的行为是类似的:
# sleep进程是当前shell进程的子进程
$ (sleep 30)
# 当前shell进程会创建一个子bash进程
# sleep进程和echo进程是该子bash进程的子进程
$ (sleep 30 ; echo hhh)
了解以上插曲后,想必能清晰地理解如下结论:
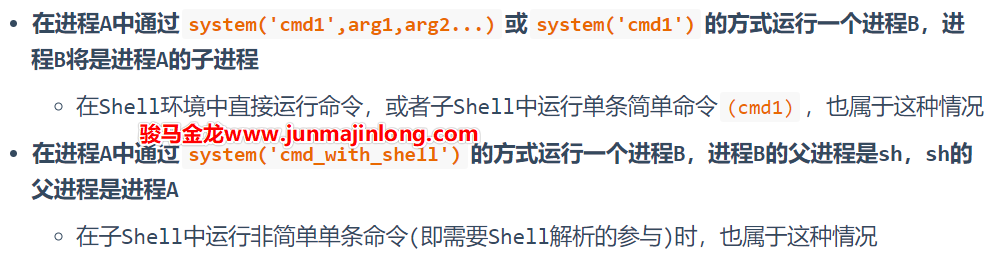
孤儿进程和Daemon类进程
如果在进程B退出前,父进程先退出了呢?这时进程B将成为孤儿进程,因为它的父进程已经死了。
孤儿进程会被PID=1的systemd进程收养,所以进程B的父进程PPID会从原来的进程A变为PID=1的systemd进程。
注意,孤儿进程会继续保持运行,而不会随父进程退出而终止,只不过其父进程发生了改变。
例如,在子Shell中运行后台命令:
$ (sleep 30 &)
因为后台符号&是属于Shell的,所以涉及到shell的解析过程,所以当前bash进程会创建一个子bash进程来解析命令并提供sleep进程的运行环境。
sleep进程将在这个子bash进程环境中运行,但因为它是一个后台命令,所以sleep进程创建成功之后立即返回,由于小括号内已经没有其它命令,子bash进程会立即终止。这意味着sleep将成为孤儿进程:
$ ps -o pid,ppid,cmd $(pgrep sleep)
PID PPID CMD
32843 1 sleep 30
再比如,Shell脚本内部运行一个后台命令,并且让Shell脚本在后台命令退出前先退出。
#!/bin/bash
sleep 300 &
echo over
当上述脚本运行时,sleep在后台运行并立即返回,于是立即执行echo进程,echo执行完成后脚本进程退出。
脚本进程退出前,sleep进程的父进程为脚本进程,脚本进程退出后,sleep进程成为孤儿进程继续运行,它会被systemd进程收养,其父进程变成PID=1。
当一个进程脱离了Shell环境后,它就可以被称为后台服务类进程,即Daemon类守护进程,显然Daemon类进程的PPID=1。当某进程脱离Shell的控制,也意味着它脱离了终端:当终端断开连接时,不会影响这些进程。
需特别关注的是创建Daemon类进程的流程:先有一个父进程,父进程在某个时间点fork出一个子进程继续运行代码逻辑,父进程立即终止,该子进程成为孤儿进程,即Daemon类进程。当然,要创建一个完善的Daemon类进程还需考虑其它一些事情,比如要独立一个会话和进程组,要关闭stdin/stdout/stderr,要chdir到/下防止文件系统错误导致进程异常,等等。不过最关键的特性仍在于其脱离Shell、脱离终端。
为什么要fork一个子进程作为Daemon进程?为什么父进程要立即退出?
所有的Daemon类进程都要脱离Shell脱离终端,才能不受终端不受用户影响,从而保持长久运行。
在代码层面上,脱离Shell脱离终端是通过setsid()创建一个独立的Session实现的,而进程组的首进程(pg leader)不允许创建新的Session自立山头,只有进程组中的非首进程(比如进程组首进程的子进程)才能创建会话,从而脱离原会话。
而Shell命令行下运行的命令,总是会创建一个新的进程组并成为leader进程,所以要让该程序成为长久运行的Daemon进程,只能创建一个新的子进程来创建新的session脱离当前的Shell。
另外,父进程立即退出的原因是可以立即将终端控制权交还给当前的Shell进程。但这不是必须的,比如可以让子进程成为Daemon进程后,父进程继续运行并占用终端,只不过这种代码不友好罢了。
换句话说,当用户运行一个Daemon类程序时,总是会有一个瞬间消失的父进程。
前面演示的几个孤儿进程示例已经说明了这一点。为了更接近实际环境,这里再用nginx来论证这个现象。
默认配置下,nginx以daemon方式运行,所以nginx启动时会有一个瞬间消失的父进程。
$ ps -o pid,ppid,comm; nginx; ps -o pid,ppid,comm $(pgrep nginx)
PID PPID COMMAND
34126 34124 bash
34194 34126 ps
PID PPID COMMAND
34196 1 nginx
34197 34196 nginx
34198 34196 nginx
34200 34196 nginx
34201 34196 nginx
第一个ps命令查看到当前分配到的PID值为34194,下一个进程的PID应该分配为34195,但是第二个ps查看到nginx的main进程PID为34196,中间消失的就是nginx main进程的父进程。
可以修改配置文件使得nginx以非daemon方式运行,即在前台运行,这样nginx将占用终端,且没有中间的父进程,占用终端的进程就是main进程。
$ ps -o pid,ppid,comm; nginx -g 'daemon off;' &
PID PPID COMMAND
34126 34124 bash
34439 34126 ps #--> ps PID=34439
[1] 34440 #--> NGINX PID=34440
[~]->$ ps -o pid,ppid,comm $(pgrep nginx)
PID PPID COMMAND
34440 34126 nginx
34445 34440 nginx
34446 34440 nginx
34447 34440 nginx
34448 34440 nginx
最后,需要区分后台进程和Daemon类进程,它们都在后台运行。但普通的后台进程仍然受shell进程的监督和管理,用户可以将其从后台调度到前台运行,即让其再次获得终端控制权。而Daemon类进程脱离了终端、脱离了Shell,它们不再受Shell的监督和管理,而是接受pid=1的systemd进程的管理。
systemd时代的服务管理
systemd时代的服务管理
使用systemd做服务管理时,需要了解一些基本知识:
- 了解systemd可管理哪些服务
- 了解systemd所管理服务的状态
- 了解systemctl管理服务的基本命令
- 学会编写、修改、看懂服务Unit配置文件
此处介绍前(3)点相关的内容,第(4)点内容较多,后面的文章再详细介绍。
systemd可管理哪些服务
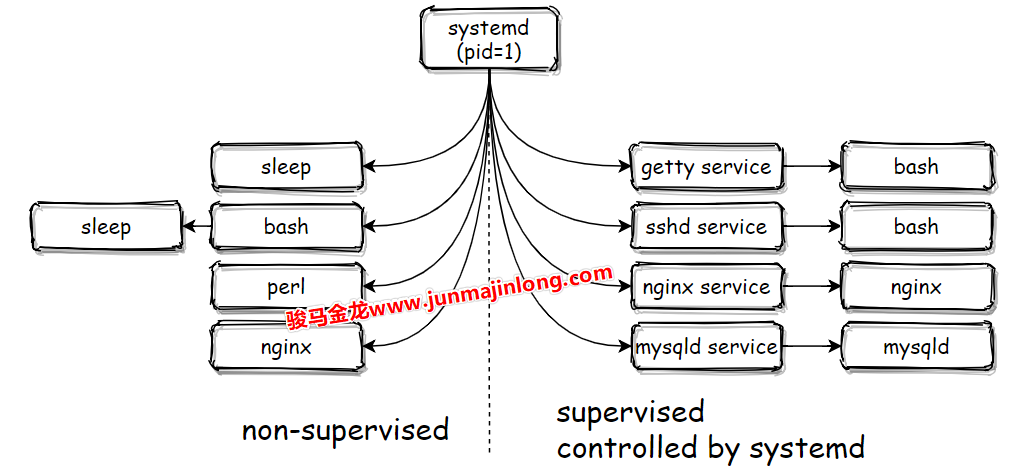
操作系统使用systemd后,所有用户进程都是systemd的后代进程。
$ pstree -p
systemd(1)─┬─agetty(1056)
├─auditd(737)───{auditd}(738)
├─crond(810)
├─dbus-daemon(761)
├─dhclient(966)
├─irqbalance(764)
├─lvmetad(573)
├─master(1140)─┬─pickup(1141)
│ └─qmgr(1142)
├─mysqld(1068)─┬─{mysqld}(1161)
│ └─......
├─polkitd(763)─┬─{polkitd}(814)
│ ├─......
├─rpcbind(762)
├─rsyslogd(1047)─┬─{rsyslogd}(1093)
│ └─{rsyslogd}(1094)
├─sshd(1042)───sshd(1110)─┬─bash(1143)───pstree(2240)
│ └─bash(1492)
├─systemd-journal(545)
├─systemd-logind(773)
├─systemd-udevd(576)
└─tuned(1024)─┬─{tuned}(1377)
├─{tuned}(1378)
├─{tuned}(1380)
└─{tuned}(1381)
当某个进程不在某个绑定了终端的Shell进程下,该进程必然是脱离终端脱离Shell的Daemon类进程或其子孙进程。
虽然从进程树关系来看,所有进程都直接或间接地受到systemd的管理,但是,并非所有systemd的子进程都受Systemd Unit管理单元的管理。只有那些由systemd方式启动的服务进程(比如systemctl命令启动)才受到Systemd Unit管理单元的监控和管理。为了简化描述,后面均直接以『systemd管理』来描述受systemd unit管理单元的管理。
比如,用户可以通过下面两种方式启动Nginx服务进程:
nginx # (1)
systemctl start nginx # (2)
但systemd只能监控、管理第(2)种方式启动的nginx服务。比如第一种方式启动的nginx,无法使用systemctl stop nginx来停止。
所以,systemd下的直系子进程可分为两类:受systemd管理的子进程和不受systemd管理的子进程。
systemd管理服务的命令
注,下面这些命令可同时操作多个服务,且可对服务名称做模式匹配。
启动、停止服务:
systemctl start Service_Name1 Service_Name2
systemctl stop Service_Name
服务重载、重启相关操作:
# 重载服务:服务未运行时不做任何事
systemctl reload Service_Name
# 重启服务:服务已运行时重启之,服务未运行时启动之
systemctl restart Service_Name
# 服务已运行时重启之,未运行时不启动之
systemctl try-restart Service_Name
# 服务已运行时,如果支持reload,则reload,如果不支持则restart
# 服务未运行时,启动之
systemctl reload-or-restart Service_Name
# 服务已运行时,如果支持reload,则reload,如果不支持则restart
# 服务未运行时,不做任何事
systemctl reload-or-try-restart Service_Name
服务状态查看操作:
# 查看服务状态
systemctl status Service_Name
# 检查服务是否active: 服务是否已启动
# 至少一个服务active时,返回0,否则返回非0退出状态码
systemctl is-active Service_Name1 Service_Name2
systemctl --quiet is-active Service_Name # 静默模式
# 检查服务是否failed: 服务启动命令退出状态码非0或启动超时
systemctl is-failed Service_Name
systemd所管理服务的状态说明
当使用systemd管理服务时,有必要了解服务的各种状态信息。
使用systemctl list-units --type=service可以列出Service Unit的状态信息:
$ systemctl list-units --type service
UNIT LOAD ACTIVE SUB DESCRIPTION
auditd.service loaded active running Security Auditing Service
cgconfig.service loaded active exited Control Group configuration service
crond.service loaded active running Command Scheduler
......
mysqld.service loaded active running MySQL Server
network.service loaded active running LSB: Bring up/down networking
● nginx.service loaded failed failed The nginx HTTP and reverse proxy server
polkit.service loaded active running Authorization Manager
postfix.service loaded active running Postfix Mail Transport Agent
......
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type
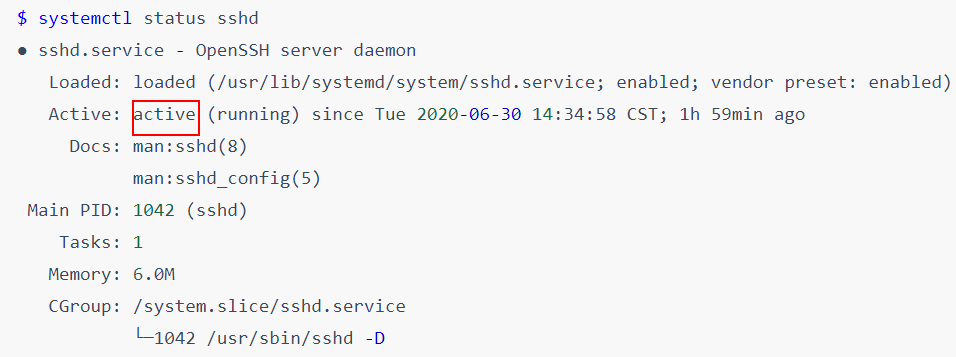
使用systemctl status Service_Name命令可以查看到服务的状态信息。
$ systemctl status sshd
● sshd.service - OpenSSH server daemon
Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2020-06-30 14:34:58 CST; 1h 59min ago
Docs: man:sshd(8)
man:sshd_config(5)
Main PID: 1042 (sshd)
Tasks: 1
Memory: 6.0M
CGroup: /system.slice/sshd.service
└─1042 /usr/sbin/sshd -D
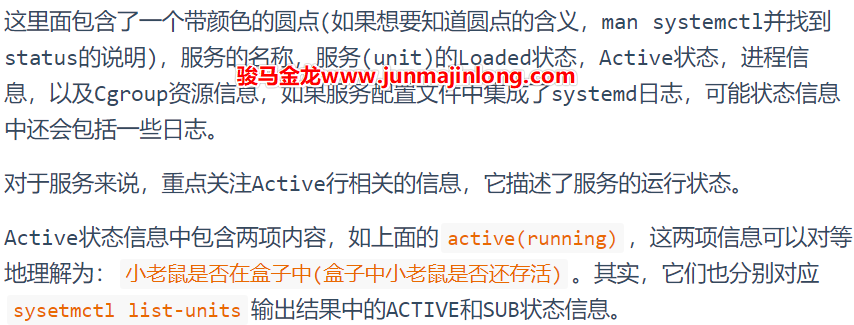
第一项状态信息描述systemd是否在监控服务进程。可能的状态值有:
- active
- inactive
- activating或deactivating
- reloading
- failed
如果一个服务已经启动成功,它将成功加入到systemd监控队列(job queue),此后它将受到systemd监控和管理,此时该服务的状态为active。
如果一个服务在启动过程中失败,比如负责服务启动的命令(ExecStart指令所指定)在启动时以非0退出状态码退出、服务启动过程耗时过久导致超时、进程崩溃等,此时该服务的状态将处于failed状态,表示加入监控队列失败,事实上它加入到了某个描述启动失败的队列中。
当一个服务未启动,或者服务已停止时,该服务的状态将处于inactive状态。
有些服务启动、停止可能会消耗一点时间,在启动或停止的过程中去查看服务的状态,看到的状态信息可能会是activating或deactivating或reloading。
Active状态行的第二项状态信息描述被监控进程的进程状态。它可能的状态值有很多(部分机器如Ubuntu可使用systemctl --state=help查看支持的值),且随着版本的更迭,支持的值也会发生变化。如下是ubuntu 18.04 systemd 237版本中查看到的值:
dead
start-pre
start
start-post
running
exited
reload
stop
stop-sigabrt
stop-sigterm
stop-sigkill
stop-post
final-sigterm
final-sigkill
failed
auto-restart
虽然有很多种状态,但用户通常只需关注其中几项常见的即可。并且这些状态的存在通常都依赖于第一项active状态,比如active(running)、active(exited)。
running状态表明被systemd监控的服务进程正在运行。
dead状态表明被systemd监控的进程已经死了(终结了),systemd识别到这种状态后就会将其从监控队列中释放并不再监控它,所以它的第一项状态也会随之变为inactive。以下几种情况都会使得服务进入dead状态:
exited表明被systemd监控的服务进程已经退出了或者systemd找不到它本该要监控的进程,但是管理者systemd认为它还没有死,只是认为它暂时退出了,所以通常会结合active状态一起出现,即active(exited),这种状态表明了一种意愿:服务进程已经消失了,但依然认为服务进程是活动的且正被监控。例如,当服务配置文件中配置了RemainAfterExit=true时,服务在退出后会进入active(exited)状态,还有多种其它可能会进入这种状态,通常来说意味着服务启动不正常(比如配置文件错误),但并非一定代表服务是失败的,它仍然可能会正常提供服务。
auto-restart表明服务正在被systemd自动重启中,当服务配置文件设置了Restart且符合Restart规则时systemd会自动重启服务。
systemd service之:服务配置文件编写(1)
systemd服务配置文件编写(1)
systemd service:简介
Systemd Service是systemd提供的用于管理服务启动、停止和相关操作的功能,它极大的简化了服务管理的配置过程,用户只需要配置几项指令即可。相比于SysV的服务管理脚本,用户不需要去编写服务的启动、停止、重启、状态查看等等一系列复杂且有重复造轮子嫌疑的脚本代码了,相信写过SysV服务管理脚本的人都深有体会。所以,Systemd Service是面向所有用户的,即使对于新手用户来说,配置门槛也非常低。
systemd service是systemd所管理的其中一项内容。实际上,systemd service是Systemd Unit的一种,除了Service,systemd还有其他几种类型的unit,比如socket、slice、scope、target等等。在这里,暂时了解两项内容:
- Service类型,定义服务程序的启动、停止、重启等操作和进程相关属性
- Target类型,主要目的是对Service(也可以是其它Unit)进行分组、归类,可以包含一个或多个Service Unit(也可以是其它Unit)
此外,Systemd作为管家,还将一些功能集成到了Systemd Service中,个人觉得比较出彩的两个集成功能是:
- 用户可以直接在Service配置文件中定义CGroup相关指令来对该服务程序做资源限制。在以前,对服务程序做CGroup资源控制的步骤是比较繁琐的
- 用户可以选择Journal日志而非采用rsyslog,这意味着用户可以不用单独去配置rsyslog,而且可以直接通过systemctl或journalctl命令来查看某服务的日志信息。当然,该功能并不适用于所有情况,比如用户需要管理日志时
Systemd Service还有其它一些特性,比如可以动态修改服务管理配置文件,比如可以并行启动非依赖的服务,从而加速开机过程,等等。例如,使用systemd-analyze blame可分析开机启动各服务占用的时长:
$ systemd-analyze blame
3.557s network.service
1.567s lvm2-pvscan@8:2.service
1.060s lvm2-monitor.service
1.046s dev-mapper-centos\x2droot.device
630ms cgconfig.service
581ms tuned.service
488ms mysqld.service
270ms postfix.service
138ms auditd.service
91ms polkit.service
66ms boot.mount
43ms systemd-logind.service
......
# 从内核启动开始至开机结束所花时间
$ systemd-analyze time
Startup finished in 818ms (kernel) + 2.228s (initrd) + 3.325s (userspace) = 6.372s
multi-user.target reached after 2.214s in userspace
systemd服务配置文件存放路径

如果用户需要,可以将服务配置文件手动存放至用户配置目录/etc/systemd/system下。该目录下的服务配置文件可以是普通.service文件,也可以是链接至/usr/lib/systemd/system目录下服务配置文件的软链接。
例如:
# 位于/usr/lib/systemd/system下的服务配置文件
# 注意带有`@`符号的文件名,它有特殊意义
$ ls -1 /usr/lib/systemd/system/*.service | head
/usr/lib/systemd/system/arp-ethers.service
/usr/lib/systemd/system/auditd.service
/usr/lib/systemd/system/[email protected]
/usr/lib/systemd/system/blk-availability.service
/usr/lib/systemd/system/brandbot.service
/usr/lib/systemd/system/cgconfig.service
/usr/lib/systemd/system/cgred.service
/usr/lib/systemd/system/console-getty.service
/usr/lib/systemd/system/console-shell.service
/usr/lib/systemd/system/[email protected]
# 下面这些目录(*.target.wants)定义各种类型下需要运行的服务
# 如:
# sysinit.target.wants目录下的是系统初始化过程运行的服务
# getty.target.wants目录下的是开机后启动虚拟终端时运行的服务
# multi-user.target.wants目录下的是多用户模式(对应运行级别2、3、4)下运行的服务
$ ls -1dF /etc/systemd/system/*
/etc/systemd/system/basic.target.wants/
/etc/systemd/system/default.target
/etc/systemd/system/default.target.wants/
/etc/systemd/system/getty.target.wants/
/etc/systemd/system/local-fs.target.wants/
/etc/systemd/system/multi-user.target.wants/
/etc/systemd/system/nginx.service.d/
/etc/systemd/system/sockets.target.wants/
/etc/systemd/system/sysinit.target.wants/
/etc/systemd/system/system-update.target.wants/
# /etc/systemd/system/multi-user.target.wants下的服务配置文件,几乎都是软链接
$ ls -l /etc/systemd/system/multi-user.target.wants/ | awk '{print $9,$10,$11}'
auditd.service -> /usr/lib/systemd/system/auditd.service
crond.service -> /usr/lib/systemd/system/crond.service
irqbalance.service -> /usr/lib/systemd/system/irqbalance.service
mysqld.service -> /usr/lib/systemd/system/mysqld.service
postfix.service -> /usr/lib/systemd/system/postfix.service
remote-fs.target -> /usr/lib/systemd/system/remote-fs.target
rhel-configure.service -> /usr/lib/systemd/system/rhel-configure.service
rsyslog.service -> /usr/lib/systemd/system/rsyslog.service
sshd.service -> /usr/lib/systemd/system/sshd.service
tuned.service -> /usr/lib/systemd/system/tuned.service
systemd service文件格式说明
一个Systemd Service的服务配置文件大概长这样:
[Unit]
Description = some descriptions
Documentation = man:xxx(8) man:xxx_config(5)
Requires = xxx1.target xxx2.target
After = yyy1.target yyy2.target
[Service]
Type = <TYPE>
ExecStart = <CMD_for_START>
ExecStop = <CMD_for_STOP>
ExecReload = <CMD_for_RELOAD>
Restart = <WHEN_TO_RESTART>
RestartSec = <TIME>
[Install]
WantedBy = xxx.target yy.target
一个.Service配置文件分为三部分:
- Unit:定义该服务作为Unit角色时相关的属性
- Service:定义本服务相关的属性
- Install:定义本服务在设置服务开机自启动时相关的属性。换句话说,只有在创建/移除服务配置文件的软链接时,Install段才会派上用场。这一配置段不是必须的,当未配置
[Install]时,设置开机自启动或禁止开机自启动的操作将无任何效果
[Unit]和[Install]段的配置指令都来自于man systemd.unit,这些指令都用于描述作为Unit时的属性,[Service]段则专属于.Service服务配置文件。
这里先介绍一些常见的[Unit]和[Install]相关的指令(虽然支持的配置指令很多,但只需熟悉几个即可),之后再专门介绍Service段落的配置指令。
[Unit]段落指令
| Unit指令 | 含义 |
|---|---|
| Description | Unit的描述信息 |
| Documentation | 本Unit的man文档路径 |
| After | 本服务在哪些服务启动之后启动,仅定义启动顺序,不定义服务依赖关系,即使要求先启动的服务启动失败,本服务也依然会启动 |
| Before | 本服务在哪些服务启动之前启动,仅定义启动顺序,不定义服务依赖关系。通常用于定义在关机前要关闭的服务,如Before=shutdown.target |
| Wants | 本服务在哪些服务启动之后启动,定义服务依赖关系,不定义服务启动顺序。启动本服务时,如果被依赖服务未启动,则也会启动被依赖服务。如果被依赖服务启动失败,本服务不会受之影响,因此本服务会继续启动。如果未结合After使用,则本服务和被依赖服务同时启动。 当配置在 [Install]段落中时,systemctl enable操作将会将本服务安装到对应的.wants目录下(在该目录下创建一个软链接),在开机自启动时,.wants目录中的服务会被隐式添加至目标Unit的Wants指令后。 |
| Requires | 本服务在哪些服务启动之后启动,定义服务强依赖关系,不定义服务启动顺序。启动本服务时,如果被依赖服务未启动,则也会启动被依赖服务。如果结合了After,当存在非active状态的被依赖服务时,本服务不会启动。且当被依赖服务被手动停止时,本服务也会被停止,但有例外。如果要保证两服务之间状态必须一致,使用BindsTo指令。 当配置在 [Install]段落中时,systemctl enable操作将会将本服务安装到对应的.requires目录下(在该目录下创建一个软链接),在开机自启动时,.requires目录中的服务会被隐式添加至目标Unit的Requires指令后。 |
| Requisite | 本服务在哪些服务启动之后启动,定义服务依赖关系,不定义服务启动顺序。启动本服务时,如果被依赖服务处于尚未启动状态,则不会主动去启动这些服务,所以本服务直接启动失败。该指令一般结合After一起使用,以便保证启动顺序。 |
| BindsTo | 绑定两个服务,两服务的状态保证一致。如服务1为active,则本服务也一定为active。 |
| PartOf | 本服务是其它服务的一部分,定义了单向的依赖关系,且只对stop和restart操作有效。当被依赖服务执行stop或restart操作时,本服务也会执行操作,但本服务执行这些操作,不会影响被依赖服务。一般用于组合target使用,比如a.service和b.service都配置PartOf=c.target,那么stop c的时候,也会同时stop a和b。 |
| Conflicts | 定义冲突的服务,本服务和被冲突服务的状态必须相反。当本服务要启动时,将会停止目标服务,当启动目标服务时,将会停止本服务。启动和停止的操作同时进行,所以,如果想要让本服务在目标服务启动之前就已经处于停止状态,则必须定义After/Before。 |
| OnFailure | 当本服务处于failed时,将启动目标服务。如果本服务配置了Restart重启指令,则在耗尽重启次数之后,本服务才会进入failed。 有时候这是非常有用的,一个典型用法是本服务失败时调用定义了邮件发送功能的service来发送邮件,特别地,可以结合systemd.timer定时任务实现cron的MAILTO功能。 |
| RefuseManualStart, RefuseManualStop | 本服务不允许手动启动和手动停止,只能被依赖时的启动和停止,如果手动启动或停止,则会报错。有些特殊的服务非常关键,或者某服务作为一个大服务的一部分,为了保证安全,都可以使用该特性。例如,系统审计服务auditd.service中配置了不允许手动停止指令RefuseManualStop,network.target中配置了不允许手动启动指令RefuseManualStart。 |
| AllowIsolated | 允许使用systemctl isolate切换到本服务,只配置在target中。一般来说,用户服务是绝不可能用到这一项的。 |
| ConditionPathExists, AssertPathExists | 要求给定的绝对路径文件已经存在,否则不做任何事(condition)或进入failed状态(assert),可在路径前使用!表示条件取反,即不存在时才启动服务。 |
| ConditionPathIsDirectory, AssertPathIsDirectory | 如上,路径存在且是目录时启动。 |
| ConditionPathIsReadWrite, AssertPathIsReadWrite | 如上,路径存在且可读可写时启动。 |
| ConditionDirectoryNotEmpty, AssertDirectoryNotEmpty | 如上,路径存在且是非空目录时启动。 |
| ConditionFileNotEmpty, AssertFileNotEmpty | 如上,路径存在且是非空文件时启动。 |
| ConditionFileIsExecutable, AssertFileIsExecutable | 如上,路径存在且是可执行普通文件时启动。 |
对于自定义的服务配置文件来说,需要定义的常见指令包括Description、After、Wants及可能需要的条件判断类指令。所以,Unit段落是非常简单的。
[Install]段落指令
下面是[Install]段落相关的指令,它们只在systemctl enable/disable操作时有效。如果期望服务开机自启动,一般只配置一个WantedBy指令,如果不期望服务开机自启动,则Install段落通常省略。
| Install指令 | 含义 |
|---|---|
| WantedBy | 本服务设置开机自启动时,在被依赖目标的.wants目录下创建本服务的软链接。例如WantedBy = multi-user.target时,将在/etc/systemd/multi-user.target.wants目录下创建本服务的软链接。 |
| RequiredBy | 类似WantedBy,但是是在.requires目录下创建软链接。 |
| Alias | 指定创建软链接时链接至本服务配置文件的别名文件。例如reboot.target中配置了Alias=ctrl-alt-del.target,当执行enable时,将创建/etc/systemd/system/ctrl-alt-del.service软链接并指向reboot.target。 |
| DefaultInstance | 当是一个模板服务配置文件时(即文件名为[email protected]),该指令指定该模板的默认实例。例如[email protected]中配置了DefaultInstall=server时,systemctl enable [email protected]时将创建名为[email protected]的软链接。 |
例如,下面是sshd的服务配置文件/usr/lib/systemd/system/sshd.service,只看Unit段落和Install段落,是否很简单?
再来一个auditd.service的配置文件示例:
$ cat /usr/lib/systemd/system/auditd.service
[Unit]
Description=Security Auditing Service
DefaultDependencies=no
After=local-fs.target systemd-tmpfiles-setup.service
Before=sysinit.target shutdown.target # 关机前先停止服务
Conflicts=shutdown.target # 确保关机时,auditd已停止成功
RefuseManualStop=yes # 禁止手动systemctl stop auditd操作
ConditionKernelCommandLine=!audit=0
Documentation=man:auditd(8)
[Service]
......
[Install]
WantedBy=multi-user.target
[Service]段配置
Systemd Service配置文件中的[Service]段落可配置的指令很多,可配置在此段落中的指令来源有多处,包括:

例如,/usr/lib/systemd/system/rsyslog.service文件的内容:
[Service]
EnvironmentFile=-/etc/sysconfig/rsyslog # 来自systemd.exec
UMask=0066 # 来自systemd.exec
StandardOutput=null # 来自systemd.exec
Type=notify # 来自systemd.service
ExecStart=/usr/sbin/rsyslogd -n $SYSLOGD_OPTIONS # 来自systemd.service
Restart=on-failure # 来自systemd.service
再比如,想要限制一个服务最多允许使用300M内存(比如512M的vps主机运行一个比较耗内存的博客系统时,可设置内存使用限制),最多30%CPU时间:
[Service]
MemoryLimit=300M
CPUQuota=30%
ExecStart=xxx
此外还需要了解systemd的一项功能,systemctl set-property,它可以在线修改已启动服务的属性。例如
# 直接限制,且写入配置文件,所以下次启动服务也会被限制
systemctl set-property nginx MemoryLimit=100M
# 直接限制,不写入配置文件,所以下次启动服务不会被限制
systemctl set-property nginx MemoryLimit=100M --runtime
目前来说,可以不用过多关注来自其它位置的指令,应该给予重点关注的是来自systemd.service自身的指令,比如:
- Type:指定服务的管理类型
- ExecStart:指定启动服务时执行的命令行
- ExecStop:指定停止服务时运行的命令
- ExecReload:指定重载服务进程时运行的命令
- Restart:指定systemd是否要自动重启服务进程以及什么情况下重启
特别是Type指令,它直接影响[Service]段中的多项配置方式。
下面将从Type指令开始引入Service段的配置方式。
根据man systemd.service,Type指令支持多种值:
- simple
- exec
- forking
- oneshot
- dbus
- notify
- idle
如果配置的是服务进程,Type的值很可能是forking或simple,如果是普通命令的进程,Type的值可能是simple、oneshot。而dbus类型一般情况下用不上,notify要求服务程序中使用代码对systemd notify进行支持,所以多数情况下可能也用不上。
关于Type,内容较长,见下一篇文章systemd service之:服务配置文件编写(2)。
systemd service之:服务配置文件编写(2)
systemd服务配置文件编写(2)
接下来会通过示例来描述不同Service Type值的应用场景。在此之前,强烈建议先阅读前后台进程父子关系和daemon类进程来搞懂进程之间的关系和Daemon类进程的特性。
systemd service:Type=forking
当使用systemd去管理一个长久运行的服务进程时,最常用的Type是forking类型。
使用Type=forking时,要求ExecStart启动的命令自身就是以daemon模式运行的。而以daemon模式运行的进程都有一个特性:总是会有一个瞬间退出的中间父进程,如果不了解这点特性,请看前后台进程父子关系和daemon类进程。
例如,nginx命令默认以daemon模式运行,所以可直接将其配置为forking类型:
$ cat test.service
[Unit]
Description = Test
[Service]
Type = forking
ExecStart = /usr/sbin/nginx
$ systemctl daemon-reload
$ systemctl start test
$ systemctl status test
● test.service - Test
Loaded: loaded
Active: active (running)
Process: 7912 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS)
Main PID: 7913 (nginx)
Tasks: 5
Memory: 4.6M
CGroup: /system.slice/test.service
├─7913 nginx: master process /usr/sbin/nginx
├─7914 nginx: worker process
├─7915 nginx: worker process
├─7916 nginx: worker process
└─7917 nginx: worker process
注意上面status报告的信息中,ExecStart启动的nginx的进程PID=7912,且该进程的状态是已退出,退出状态码为0,这个进程是daemon类进程创建过程中瞬间退出的中间父进程。在forking类型中,该进程称为初始化进程。同时还有一行Main PID: 7913 (nginx),这是systemd真正监控的nginx服务主进程,其PID=7913,是PID=7912进程的子进程。
Type=forking类型代表什么呢?要解释清楚该type,需从进程创建开始说起。

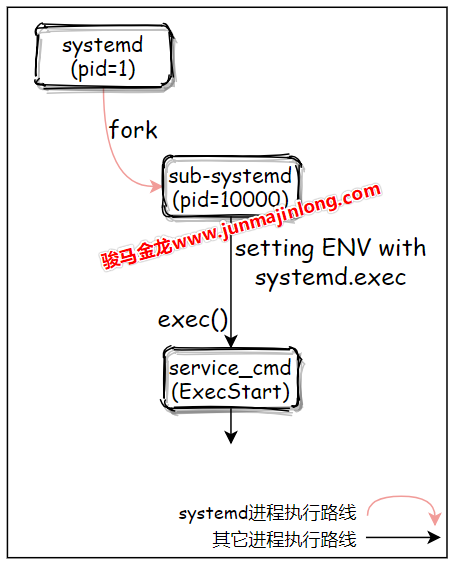
对于Type=forking来说,pid=1的systemd进程fork出来的子进程正是瞬间退出的中间父进程,且systemd会在中间父进程退出后就认为服务启动成功,此时systemd可以立即去启动后续需要启动的服务。
如果Type=forking服务中的启动命令是一个前台命令会如何呢?比如将sleep配置为forking模式,将nginx daemon off配置为forking模式等。
答案是systemd会一直等待中间ExecStart启动的进程作为中间父进程退出,在等待过程中,systemctl start会一直卡住,直到等待超时而失败,在此阶段中,systemctl status将会查看到服务处于activating状态。
$ cat test.service
[Unit]
Description = Test
[Service]
Type = forking
ExecStart = /usr/sbin/nginx -g 'daemon off;'
$ systemctl daemon-reload
$ systemctl start test # 卡住
$ systemctl status test # 另一个窗口查看
● test.service - Test
Loaded: loaded
Active: activating (start)
Control: 9227 (nginx)
Tasks: 1
Memory: 2.0M
CGroup: /system.slice/test.service
└─9227 /usr/sbin/nginx -g daemon off;
回到forking类型的服务。由于daemon类的进程会有一个瞬间退出的中间父进程(如上面PID=7913的nginx进程),systemd是如何知道哪个进程是应该被监控的服务主进程(Main PID)呢?
答案是靠猜。没错,systemd真的就是靠猜的。当设置Type=forking时,有一个GuessMainPID指令其默认值为yes,它表示systemd会通过一些算法去猜测Main PID。当systemd的猜测无法确定哪个为主进程时,后果是严重的:systemd将不可靠。因为systemd无法正确探测服务是否真的失败,当systemd误认为服务失败时,如果本服务配置了自动重启(配置了Restart指令),重启服务时可能会和当前正在运行但是systemd误认为失败的服务冲突(比如出现端口已被占用问题)。
多数情况下的猜测过程很简单,systemd只需去找目前存活的属于本服务的leader进程即可。但有些服务(少数)情况可能比较复杂,在多进程之间做简单的猜测并非总是可靠。
好在,Type=forking时的systemd提供了PIDFile指令(Type=forking通常都会结合PIDFile指令),systemd会从PIDFile指令所指定的PID文件中获取服务的主进程PID。
例如,编写一个nginx的服务配置文件:
$ cat test.service
[Unit]
Description = Test
[Service]
Type = forking
PIDFile = /run/nginx.pid
ExecStartPre = /usr/bin/rm -f /run/nginx.pid
ExecStart = /usr/sbin/nginx
ExecStartPost = /usr/bin/sleep 0.1
Type=forking时PIDFile指令的坑
关于PIDFile,有必要去了解一些注意事项,否则它们可能就会成为你的坑。
首先,PIDFile只适合在Type=forking模式下使用,其它时候没必要使用,因为其它类型的Service主进程的PID都是确定的。systemd推荐PIDFile指定的PID文件在/run目录下,所以,可能需要修改服务程序的配置文件,将其PID文件路径修改为/run目录之下,当然这并非必须。
但有一点必须注意,PIDFile指令的值要和服务程序的PID文件路径保持一致。
例如nginx的相关配置:
$ grep -i 'pid' /etc/nginx/nginx.conf
pid /run/nginx.pid;
$ cat /usr/lib/systemd/system/nginx.service
[Unit]
Description=The nginx HTTP and reverse proxy server
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=forking
PIDFile=/run/nginx.pid # 路径和nginx.conf中保持一致
ExecStartPre=/usr/bin/rm -f /run/nginx.pid
ExecStartPre=/usr/sbin/nginx -t
ExecStart=/usr/sbin/nginx
ExecReload=/bin/kill -s HUP $MAINPID
KillSignal=SIGQUIT
TimeoutStopSec=5
KillMode=process
PrivateTmp=true
[Install]
WantedBy=multi-user.target
其次,systemd会在中间父进程退出后立即读取这个PID文件,读取成功后就认为该服务已经启动成功。但是,systemd读取PIDFile的时候,服务主进程可能还未将PID写入到PID文件中,这时systemd将出现问题。所以,对于服务程序的开发人员来说,应尽早将主进程写入到PID文件中,比如可以在中间父进程fork完之后立即写入PID文件,然后再退出,而不是在fork出来的服务主进程内部由主进程负责写入。
上面的nginx服务配置文件是某个nginx版本yum包提供的,但却是有问题的,我曾经踩过这个坑,网上甚至将其报告为一个Bug。
上面的nginx.service文件可以正常启动服务,但无法systemctl reload,只要reload就报错,而且报错时提示kill命令语法错误。kill语法错误显然是因为没有获取到$MAINPID变量的值,而这正是因为systemd在nginx写入PID文件之前先去读取了PID文件,因为没有读取到内容,所以$MAINPID变量为空值。
解决办法是使用ExecStartPost=/usr/bin/sleep 0.1,让systemd在初始化进程(即中间父进程)退出之后耽搁0.1秒再继续向下执行,即推迟了systemd读取PID的过程,保证能让systemd从PID文件中读取到值。
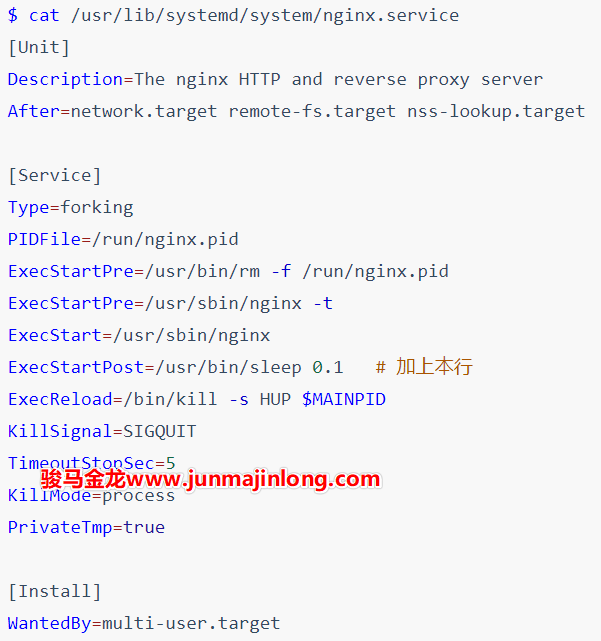
最后,systemd只会读PIDFile文件而不会写,也不会创建它。但是,在停止服务的时候,systemd会尝试删除PID文件。因为服务进程可能会异常终止,导致已终止的服务进程的PID文件仍然保留着,所以在使用PIDFile指令时,通常还会使用ExecStartPre指令来删除可能已经存在的PID文件。正如上面给出的nginx配置文件一样。
systemd service:Type=simple
Type=simple是一种最常见的通过systemd服务系统运行用户自定义命令的类型,也是省略Type指令时的默认类型。
Type=simple类型的服务只适合那些在shell下运行在前台的命令。也就是说,当一个命令本身会以daemon模式运行时,将不能使用simple,而应该使用Type=forking。比如ls命令、sleep命令、非daemon模式运行的nginx进程以及那些以前台调试模式运行的进程,在理论上都可以定义为simple类型的服务。至于为何有如此规则,稍后会解释的明明白白。
例如,编写一个/usr/lib/systemd/system/test.service运行sleep进程:
[Unit]
Description = test
[Service]
Type = simple
ExecStart = /usr/bin/sleep 10 # 命令必须使用绝对路径
使用daemon-reload重载并启动该服务进程:
$ systemctl daemon-reload
$ systemctl start test
$ systemctl status test
● test.service - Test
Loaded: loaded
Active: active (running)
Main PID: 6902 (sleep)
Tasks: 1
Memory: 96.0K
CGroup: /system.slice/test.service
└─6902 /usr/bin/sleep 10
10秒内,sleep进程以daemon模式运行在后台,就像一个服务进程一样。10秒之后,sleep退出,于是systemd将该进程从监控队列中踢出。再次查看进程的状态将是inactive:
$ systemctl status test
● test.service - Test
Loaded: loaded
Active: inactive (dead)
再来分析上面的服务配置文件中的指令。
ExecStart指令指定启动本服务时执行的命令,即启动一个本该前台运行的sleep进程作为服务进程在后台运行。
需注意,systemd service的命令行中必须使用绝对路径,且只能编写单条命令(Type=oneshot时除外),如果要命令续行,可在尾部使用反斜线符号
\等。此外,命令行中支持部分类似Shell的特殊符号,但不支持重定向
> >> << <、管道|、后台符号&,具体可参考man systemd.service中command line段落的解释说明。
对于Type=simple来说,systemd系统在fork出子systemd进程后就认为服务已经启动完成了,所以systemd可以紧跟着启动排在该服务之后启动的服务。它的伪代码模型大概是这样的:
# pid = 1: systemd
# start service1 with Type=simple
pid=fork()
if(pid=0){
# Child Process: sub systemd process
exec(<Service_Cmd>)
}
# start other services after service1
...
例如,先后连续启动两个Type=simple的服务,进程流程图大概如下:
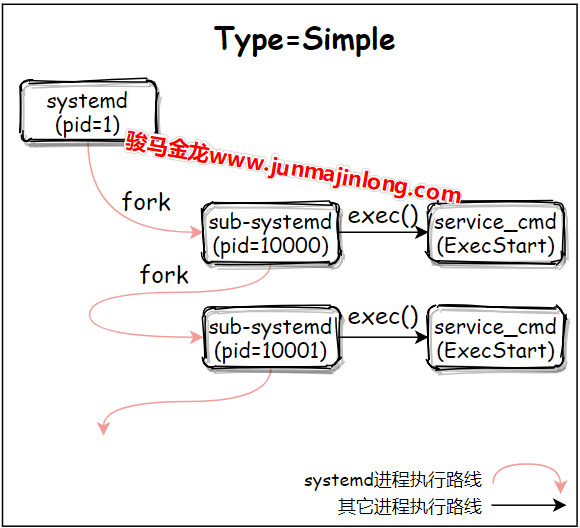
换句话说,当Type=simple时,systemd只在乎fork阶段是否成功,只要fork子进程成功,这个子进程就受systemd监管,systemd就认为该Unit已经启动。
因为子进程已成功被systemd监控,无论子进程是否启动成功,在子进程退出时,systemd都会将其从监控队列中踢掉,同时杀掉所有附属进程(默认行为是如此,杀进程的方式由systemd.kill中的KillMode指令控制)。所以,查看服务的状态将是inactive(dead)。
例如,下面的配置种,睡眠1秒后,该服务的状态将变为inactive(dead)。
[Service]
ExecStart = /usr/bin/sleep 1
这没什么疑问。但考虑一下,如果simple类型下ExecStart启动的命令本身就是以daemon模式运行的呢?其结果是systemd默认会立刻杀掉所有属于服务的进程。
原因也很简单,daemon类进程总是会有一个瞬间退出的中间父进程,而在simple类型下,systemd所fork出来的子进程正是这个中间父进程,所以systemd会立即发现这个中间父进程的退出,于是杀掉其它所有服务进程。
例如,以运行bash -c '(sleep 3000 &)'的simple类型的服务,被systemd监控的bash进程会在启动sleep后立即退出,于是systemd会立即杀掉属于该服务的sleep进程。
$ cat test.service
[Unit]
Description = Test
[Service]
ExecStart = bash -c '( sleep 3000 & )'
$ systemctl daemon-reload
$ systemctl start test
$ systemctl status test
● test.service - Test
Loaded: loaded
Active: inactive (dead)
再例如,nginx命令默认是以daemon模式运行的,simple类型下直接使用nginx命令启动服务,systemd会立刻杀掉所有nginx,即nginx无法启动成功。
$ cat test.service
[Unit]
Description = Test
[Service]
ExecStart = /usr/sbin/nginx
$ systemctl daemon-reload
$ systemctl start test
$ systemctl status test
● test.service - Test
Loaded: loaded
Active: inactive (dead)
但如果将nginx进程以非daemon模式运行,simple类型的nginx服务将正常启动:
$ cat test.service
[Unit]
Description = Test
[Service]
ExecStart = /usr/sbin/nginx -g 'daemon off;'
$ systemctl daemon-reload
$ systemctl start test
$ systemctl status test
● test.service - Test
Loaded: loaded
Active: active (running)
Main PID: 7607 (nginx)
Tasks: 5
Memory: 4.6M
CGroup: /system.slice/test.service
├─7607 nginx: master process /usr/sbin/nginx -g daemon off;
├─7608 nginx: worker process
├─7609 nginx: worker process
├─7610 nginx: worker process
└─7611 nginx: worker process
Systemd Service:其它Type类型
除了simple和forking类型,还有exec、oneshot、idle、notify和dbus类型,这里不考虑notify和dbus,剩下的exec、oneshot和idle都类似于simple类型。
- simple:在fork出子systemd进程后,systemd就认为该服务启动成功了
- exec:在fork出子systemd进程且子systemd进程exec()调用ExecStart命令成功后,systemd认为该服务启动成功
- oneshot:在ExecStart命令执行完成退出后,systemd才认为该服务启动成功
- 因为服务进程退出后systemd才继续工作,所以在未配置RemainAfterExit指令时,oneshot类型的服务永远无法出现active状态,它直接从启动状态到activating到deactivating再到dead状态
- 当结合RemainAfterExit指令时,在服务进程退出后,systemd会继续监控该Unit,所以服务的状态为
active(exited),通过这个状态可以让用户知道,该服务曾经已经运行成功,而不是从未运行过 - 通常来说,对于那些执行单次但无需长久运行的进程来说,可以采用type=oneshot,比如启动iptables,挂载文件系统的操作、关机或重启的服务等
- idle:无需考虑这种类型
模板型服务配置文件
systemd service支持简单的模板型Unit配置文件,在Unit配置文件中可以使用%n %N %p %i...等特殊符号进行占位,在systemd读取配置文件时会将这些特殊符号解析并替换成对应的值。
这些特殊符号的含义可参见man systemd.unit。通常情况下只会使用到%i或%I,其它特殊符号用到的机会较少。
使用%i %I这两个特殊符号时,要求Unit的文件名以@为后缀,即文件名格式为[email protected]。当使用systemctl管理这类服务时,@符号后面的字符会传递到Unit模板文件中的%i或%I。
例如,执行下面这些命令时,会使用abc替换[email protected]文件中的%i或%I。
systemctl start service_name@abc
systemctl status service_name@abc
systemctl stop service_name@abc
systemctl enable service_name@abc
systemctl disable service_name@abc
有时候这是很实用的。比如有些程序即是服务端程序又是客户端程序,区分客户端和服务端的方式是使用不同配置文件。
假设用户想在一个机器上同时运行xyz程序的服务端和客户端,可编写如下Unit服务配置文件:
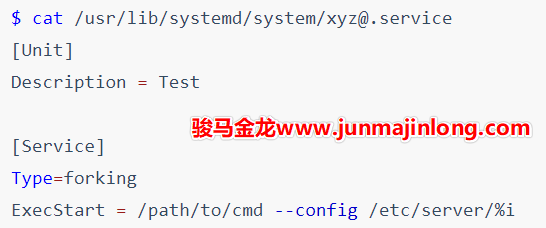
现在用户可以在/etc/server目录下同时提供服务程序的服务端配置文件和客户端配置文件。
/etc/server/server.conf
/etc/server/client.conf
如果要管理该主机上的服务端:
systemctl start xyz@server
systemctl status xyz@server
systemctl stop xyz@server
systemctl enable xyz@server
systemctl disable xyz@server
如果要管理该主机上的客户端:
systemctl start xyz@client
systemctl status xyz@client
systemctl stop xyz@client
systemctl enable xyz@client
systemctl disable xyz@client
使用target组合多个服务
有些时候,一个大型服务可能由多个小服务组成。
比如c服务由a.service和b.service组成,因为组合了两个服务,所以c服务可以定义为c.target。
a.service内容:
[Unit]
Description = a.service
PartOf = c.target
Before = c.target
[Install]
ExecStart = /path/to/a.cmd
b.service内容:
[Unit]
Description = b.service
PartOf = c.target
Before = c.target
[Install]
ExecStart = /path/to/b.cmd
c.target内容:
[Unit]
Description = c.service, consists of a.service and b.service
After = a.service b.service
Wants = a.service b.service
c中配置Wants表示a和b先启动,但启动失败不会影响c的启动。如果要求c.target和a.service、b.service的启动状态一致,可将Wants替换成Requires或BindsTo指令。
PartOf指令表明a.service和b.service是c.target的一部分,停止或重启c.target的同时,也会停止或重启a和b。再加上c.target中配置了Wants指令(也可以改成Requires或BindsTo),使得启动c的时候,a和b也已经启动完成。
但是要注意,PartOf是单向的,停止和重启a或b的时候不会影响c。
systemd时代的开机自启动任务
systemd时代的开机自启动任务
如果要让任务开机自启动,需将对应的Unit文件存放于/etc/systemd/system下。本文以Service Unit为例,但也支持让path Unit、timer Unit等类型的任务开机自启动。
systemd中服务开机自启动
用户可以手动将服务配置文件存放至此路径,但更建议采用systemd系统提供的上层工具systemctl来操作。
# 将服务加入开机自启动
systemctl enable Service_Name
# 禁止服务开机自启动
systemctl disable Service_Name
# 查看服务是否开机自启动
systemctl is-enabled Service_Name
# 查看所有开机自启动服务
systemctl list-unit-files --type service | grep 'enabled'
使用systemctl命令时,可以指定服务名称,也可以指定服务对应的服务配置unit文件。
例如下面两条命令是等价的。
systemctl enable sshd # 服务名
systemctl enable sshd.service # 服务对应的unit文件
systemctl的很多操作都具备幂等性,这意味着如果要操作的服务已经处于目标状态,则什么都不会做。
比如systemctl启动服务sshd,但如果sshd服务已经处于目标状态:已启动,则本次启动什么操作也不做,systemctl会直接退出。再比如上面将sshd加入开机自启动的操作,sshd服务在安装openssh-server的时候就已经自动加入了开机自启动,用户再手动加入开机自启动,实际上什么也不会做。
如果是未开机自启动的服务加入开机自启动呢?比如,拷贝sshd服务的配置文件,并将拷贝后的服务sshd1加入开机自启动:
$ cp /usr/lib/systemd/system/{sshd,sshd1}.service
$ systemctl enable sshd1
Created symlink from /etc/systemd/system/multi-user.target.wants/sshd1.service to /usr/lib/systemd/system/sshd1.service.
从结果可看到,systemctl将服务加入开机自启动的操作,实际上是在/etc/systemd/system某个target.wants目录下创建服务配置文件的软链接文件。
$ readlink /etc/systemd/system/multi-user.target.wants/sshd1.service
/usr/lib/systemd/system/sshd1.service
显然,禁用服务开机自启动的操作是移除软链接。
$ systemctl disable sshd1
Removed symlink /etc/systemd/system/multi-user.target.wants/sshd1.service.
最后,如果服务已经加入开机自启动,但想要再次加入(比如更新了/usr/lib/systemd/system下的服务配置文件),可在enable时加上–force选项:
systemctl --force enable Service_Name
systemd中自定义开机自启动命令/脚本

但更建议的方案是编写开机自启动服务,后面会专门介绍服务管理配置文件如何编写。
下面是一个简单的让命令(脚本)开机自启动的配置文件:
$ cat /usr/lib/systemd/system/mycmd.service
[Unit]
Description = some shell script
# 要求脚本具有可执行权限
ConditionFileIsExecutable=/usr/bin/some.sh
# 指定要运行的命令、脚本
[Service]
ExecStart = /usr/bin/some.sh
# 下面这段不能少
[Install]
WantedBy = multi-user.target
$ systemctl daemon-reload
$ systemctl enable mycmd.service
如果要使用/etc/rc.local的方式呢?systemd提供了rc-local.service服务来加载/etc/rc.d/rc.local文件中的命令。
$ cat /usr/lib/systemd/system/rc-local.service
# This unit gets pulled automatically into multi-user.target by
# systemd-rc-local-generator if /etc/rc.d/rc.local is executable.
[Unit]
Description=/etc/rc.d/rc.local Compatibility
ConditionFileIsExecutable=/etc/rc.d/rc.local
After=network.target
[Service]
Type=forking
ExecStart=/etc/rc.d/rc.local start
TimeoutSec=0
RemainAfterExit=yes
这个文件缺少了[Install]段且没有WantedBy,后面将会解释Install中的WantedBy表示设置该服务开机自启动时,该服务加入到哪个『运行级别』中启动。
但这个文件的注释中说明了,如果/etc/rc.d/rc.local文件存在且具有可执行权限,则systemd-rc-local-generator将会自动添加到multi-user.target中,所以,即使没有Install和WantedBy也无关紧要。
另一方面需要注意,和SysV系统在系统启动的最后阶段运行rc.local不太一样,systemd兼容的rc.local是在network.target即网络相关服务启动完成之后就启动的,这意味着rc.local可能在开机启动过程中较早的阶段就开始运行。
如果想要将命令加入到/etc/rc.local中实现开机自启动,直接写入该文件,并设置该文件可执行权限即可。
例如:
echo -e '#!/bin/bash\ndate +"%F %T" >/tmp/a.log' >>/etc/rc.d/rc.local
chmod +x /etc/rc.d/rc.local
systemd时代的运行级别
systemd时代的运行级别
在CentOS 6及之前的版本中有运行级别的概念,Systemd系统内没有直接定义运行级别的概念,但是通过Target Unit兼容模拟了运行级别。
可以查看/usr/lib/systemd/system/下的一些target文件。为了节省篇幅,下面我列出了部分target:
$ ls -l /usr/lib/systemd/system/*.target | grep -o '/.*'
# /usr/lib/systemd/system/下定义的默认运行级别:graphical
/usr/lib/systemd/system/default.target -> graphical.target
# 运行级别0-6,注意多用户模式为multi-user.target
/usr/lib/systemd/system/runlevel0.target -> poweroff.target
/usr/lib/systemd/system/runlevel1.target -> rescue.target
/usr/lib/systemd/system/runlevel2.target -> multi-user.target
/usr/lib/systemd/system/runlevel3.target -> multi-user.target
/usr/lib/systemd/system/runlevel4.target -> multi-user.target
/usr/lib/systemd/system/runlevel5.target -> graphical.target
/usr/lib/systemd/system/runlevel6.target -> reboot.target
# 紧急模式、救援模式、多用户模式和图形界面模式
/usr/lib/systemd/system/emergency.target
/usr/lib/systemd/system/rescue.target
/usr/lib/systemd/system/multi-user.target
/usr/lib/systemd/system/graphical.target
# 关机和重启相关操作
/usr/lib/systemd/system/halt.target
/usr/lib/systemd/system/poweroff.target
/usr/lib/systemd/system/shutdown.target
/usr/lib/systemd/system/reboot.target
/usr/lib/systemd/system/ctrl-alt-del.target -> reboot.target
而target的主要作用是对服务进行分组、归类。所以,只需要定义几个代表不同运行级别的target,并在不同的target中放入不同的服务程序即可(除了服务程序还可以包含其它的Unit)。
target又是如何对服务进行分组、归类的呢?作为初步了解,可在/etc/systemd/system中寻找答案。在此目录下,有一些*.target.wants目录,该目录定义了该target中包含了哪些Unit,systemd会在处理到对应target时会寻找wants后缀的目录,并加载启动该目录下的所有Unit,这就是target对服务(及其它Unit)分组的方式。
例如:
$ ls -1F /etc/systemd/system/
basic.target.wants/
default.target@
default.target.wants/
getty.target.wants/
local-fs.target.wants/
multi-user.target.wants/
nginx.service.d/
remote-fs.target.wants/
sockets.target.wants/
sysinit.target.wants/
system-update.target.wants/
# 系统环境初始化相关服务
$ ls -1 /etc/systemd/system/sysinit.target.wants/
cgconfig.service
lvm2-lvmetad.socket
lvm2-lvmpolld.socket
lvm2-monitor.service
rhel-autorelabel-mark.service
rhel-autorelabel.service
rhel-domainname.service
rhel-import-state.service
rhel-loadmodules.service
# 多用户模式下开机自启动的服务
$ ls -1 /etc/systemd/system/multi-user.target.wants/
auditd.service
crond.service
irqbalance.service
mysqld.service
nfs-client.target
postfix.service
remote-fs.target
rhel-configure.service
rpcbind.service
rsyslog.service
sshd.service
tuned.service
之所以有这些wants目录,并且其中有一些Unit文件,是因为在Service配置文件(或其它Unit)中的[Install]段落使用了WantedBy指令。例如:
$ cat /usr/lib/systemd/system/sshd.service
[Unit]
......
[Service]
......
[Install]
WantedBy=multi-user.target
当使用systemctl enable Unit_Name让Unit_Name开机自启动时,会寻找该[Install]中的WantedBy和RequiredBy,并在对应的/etc/systemd/system/xxx.target.wants或/etc/systemd/system/xxx.target.requires目录下创建软链接。
如果Service配置文件中没有定义WantedBy和RequiredBy,则systemctl enable操作不会有任何效果。
此外,可以在target配置文件内部使用Wants、Requires等表示依赖含义的指令来定义该target依赖哪些Unit。
例如:
$ cat /usr/lib/systemd/system/sysinit.target
[Unit]
Description=System Initialization
Documentation=man:systemd.special(7)
Conflicts=emergency.service emergency.target
Wants=local-fs.target swap.target # 看此行
.target文件中Wants指令定义的更符合依赖的含义,而.target.wants目录更倾向于表明该target中归类了哪些要运行的服务。
比如负责系统环境初始化的sysinit.target,其中的Wants指令定义了必须先运行且成功运行文件系统相关任务(local-fs.target和swap.target)后才运行sysinit.target,也就是开始启动.target.wants目录下的Unit。
执行systemctl list-units --type target可以查看系统当前已经加载的所有target,包括那些开机自启动过程中启动的。
$ systemctl list-units --type target
UNIT LOAD ACTIVE SUB DESCRIPTION
basic.target loaded active active Basic System
cryptsetup.target loaded active active Local Encrypted Volumes
getty.target loaded active active Login Prompts
local-fs-pre.target loaded active active Local File Systems (Pre)
local-fs.target loaded active active Local File Systems
multi-user.target loaded active active Multi-User System
network-online.target loaded active active Network is Online
network-pre.target loaded active active Network (Pre)
network.target loaded active active Network
paths.target loaded active active Paths
remote-fs.target loaded active active Remote File Systems
slices.target loaded active active Slices
sockets.target loaded active active Sockets
swap.target loaded active active Swap
sysinit.target loaded active active System Initialization
timers.target loaded active active Timers
除了上面展示的target,在/usr/lib/systemd/system目录下还有很多target。而且,只要用户想要对一类Unit进行分组归类,那么也可以自己定义target。
但需要明确的是,target可分为两类:
- 可直接切换的target(模拟运行级别)
- 不可直接切换的target
切换是什么意思?比如从当前的运行级别3切换到运行级别5,将会启动运行级别5上的所有程序以及依赖程序,并停止当前已启动但运行级别5不需要的服务程序。这就是运行级别的切换,只是停止一些服务(或程序)、并启动另外一些服务而已。
切换target也一样,比如切换到graphical.target时,会启动目标graphical.target需要的所有服务,并停止当前已运行但目标target不需要的服务。
切换target的方式如下:
# 切换到对应的target
systemctl isolate Target_Name
# 如:
systemctl isolate default.target # 切换到默认运行级别
systemctl isolate rescue.target # 切换到救援模式
# 还支持如下命令
systemctl default
systemctl resuce
systemctl emergency
systemctl halt
systemctl poweroff
systemctl reboot
可查看或设置默认的运行级别:
systemctl get-default
systemctl set-default Target_Name
设置默认运行级别,实际上是创建/etc/systemd/system/default.target指向对应target配置文件的软链接。
比如:
$ systemctl set-default multi-user.target
Removed symlink /etc/systemd/system/default.target.
Created symlink from /etc/systemd/system/default.target to /usr/lib/systemd/system/multi-user.target.
target是否可直接切换,取决于target配置文件中是否定义了AllowIsolate=yes指令。比如multi-user.target是模拟运行级别的target,肯定允许直接切换,而network.target定义的是网络启动任务,肯定不可以直接切换。
# 等价于cat /usr/lib/systemd/system/multi-user.target
$ systemctl cat multi-user.target
# /lib/systemd/system/multi-user.target
[Unit]
Description=Multi-User System
Documentation=man:systemd.special(7)
Requires=basic.target
Conflicts=rescue.service rescue.target
After=basic.target rescue.service rescue.target
AllowIsolate=yes
# 查看Unit的属性值
$ systemctl show -p AllowIsolate network.target
AllowIsolate=no
systemd时代的/etc/fstab
systemd时代的/etc/fstab
/etc/fstab文件用于指定在开机时自动挂载的分区、文件系统、远程文件系统或块设备,以及它们的挂载方式。此外,执行mount -a操作也可以重新挂载/etc/fstab中的所有挂载项。
通用格式大致如下:
# <device> <dir> <type> <options> <dump> <fsck>
/dev/sda1 /boot vfat defaults 0 0
/dev/sda2 / ext4 defaults 0 0
/dev/sda3 /home ext4 defaults 0 0
/dev/sda4 none swap defaults 0 0
使用systemd系统时,systemd接管了挂载/etc/fstab的任务。在系统启动的时候,systemd会读取/etc/fstab文件并通过systemd-fstab-generator工具将该文件转换为systemd unit来执行,从而完成挂载任务。
systemd扩展了fstab文件的定义方式,在/etc/fstab中可使用由systemd.mount提供的挂载选项,这些选项大多以x-systemd为前缀(并非所有选项都如此),合理使用这些systemd提供的选项,可以完美地解决以前使用/etc/fstab时一些痛点。
比如,systemd.mount可以让那些要求在网络可用时的文件系统在网络已经可用的情况下才去挂载,还可以定义等待网络可用的超时时间,从而避免在开机过程中长时间卡住。
再比如,systemd可以让某个挂载项自动开始挂载和自动卸载,而不是在开机时挂载后永久挂载在后台。
/etc/fstab文件格式回顾
以如下内容为例:
# <device> <dir> <type> <options> <dump> <fsck>
/dev/sda1 /boot vfat defaults 0 0
/dev/sda2 / ext4 defaults 0 0
/dev/sda3 /home ext4 defaults 0 0
/dev/sda4 none swap defaults 0 0
其中:

需要注意,如果第一列或第二列的值包含了空格,则空格使用\040代替。例如:
PARTLABEL=EFI\040SYSTEM\040PARTITION /boot vfat defaults 0 0
第一列:挂载项标识符
/etc/fstab的第一列是挂载项的标识符,用于标识哪个设备需要被挂载。
/etc/fstab支持多种标识符类型:
-
内核识别的名称,即/dev/xxx
- 如/dev/sda1、/dev/mapper/centos-root
- 需注意,强烈建议不要在/etc/fstab中使用这种标识符,因为如果有多个(SATA/SCSI/IDE)设备时,每次系统启动都能可能导致设备名称改变。但如果是lvm设备,它的设备名是持久不变的,所以安全
-
文件系统LABEL:使用时需加前缀
LABEL=,可lsblk -f或blkid查看设备对应的LABEL。如:LABEL=EFI /boot vfat defaults 0 0 -
文件系统UUID:使用时需加前缀
UUID=,可lsblk -f或blkid查看对应设备的UUID,如:UUID=0a3407de-xxxx-848e92a327a3 / ext4 defaults 0 0 -
GPT分区LABEL:使用时需加前缀
PARTLABEL=,可使用blkid查看PARTLABEL,如:PARTLABEL=EFI\040SYSTEM\040PARTITION /boot vfat defaults 0 0 PARTLABEL=GNU/LINUX / ext4 defaults 0 0 PARTLABEL=HOME /home ext4 defaults 0 0 -
GPT UUID:使用时需加前缀
PARTUUID=,可使用blkid查看PARTUUID,如:PARTUUID=98a81274-xxxx-03df048df366 / ext4 defaults 0 0
除了第一种标识方式外,其余四种标识方式以及LVM的标识符都是持久不变的,所以都可以安全地在/etc/fstab中使用。
第四列:systemd提供的一些有用的挂载技巧
systemd提供了一些以x-systemd为前缀的挂载选项,还提供了auto noauto nofail _netdev这四个选项。
auto、noauto:auto表示开机自动挂载,noauto表示开机不自动挂载(且mount -a也不自动挂载该挂载项),但如果本挂载项被其它Unit一来,则noauto时仍然会被挂载nofail:开机时,不在乎也不等待本挂载项,即使本挂载项在开机时挂载失败也无所谓_netdev:通常mount可以根据指定的文件系统类型来推测是否是网络设备,如果是网络设备,则自动安排在网络可用之后执行挂载操作,但某些时候无法推测,比如ISCSI这类依赖于网络的块设备,使用该选项可以直接告知mount这是一个网络设备
更多挂载选项参考man systemd.mount。
延迟到第一次访问时自动挂载
例如,对于一些本地文件系统,可以将挂载选项设置为:
noauto,x-systemd.automount
noauto表示开机时不要自动挂载,x-systemd.automount表示在第一次对该文件系统进行访问时自动挂载。
内核会将从触发自动挂载到挂载成功期间所有对该设备的访问缓冲下来,当挂载成功后再去访问该设备。
自动卸载设备
noauto,x-systemd.automount,x-systemd.idle-timeout=1min
这表示systemd如果发现该设备在1分钟内都处于idle状态,将自动卸载它。默认单位为秒,支持的单位有s, min, h, ms,设置为0表示永不超时。
设置远程网络设备挂载超时时长
挂载网络设备时可能会因为各种原因而长时间等待,可设置x-systemd.mount-timeout选项。如:
noauto,x-systemd.automount,x-systemd.mount-timeout=30,_netdev
x-systemd.mount-timeout=30表示systemd最多等待该设备在30秒内挂载成功。默认单位为秒,支持的单位有s, min, h, ms,设置为0表示永不超时。
存在则挂载,不存在则忽略
使用nofaile挂载选项,在挂载失败时(比如设备不存在)直接跳过。
nofail,x-systemd.device-timeout=1ms
nofail通常会结合x-systemd.device-timeout一起使用,表示等待该设备多长时间才认为可用于挂载(即判断该设备可执行挂载操作),默认等待90s,这意味着如果结合nofail时,如果挂载的设备不存在,将会卡顿90s。默认单位为秒,支持的单位有s, min, h, ms,设置为0表示永不超时。
注意区分x-systemd.device-timeout和x-systemd.mount-timeout:

关于atime的挂载选项
读、写文件都会更改atime信息,但很多时候atime这项信息是无关紧要的,它仅表示文件最近一次是何时访问的,只有那些需要实时了解atime信息的程序才在意atime是否更新。
因为atime信息保存在文件系统的inode中,所以每次更新atime都会去访问磁盘,而访问磁盘的效率是非常低的。比如对于机械硬盘来说,频繁更新atime将导致大量磁盘寻道。
如果可以放弃维护atime的读更新,将减少额外的磁盘访问,可大幅提升性能。
挂载文件系统时,可以通过atime相关的挂载选项控制如何更新atime,从而在文件系统层次保证不会因为频繁更新atime而降低文件系统性能。
atime相关挂载选项有:
-
strictatime:每次访问文件时都更新文件的atime,显然这会严重降低文件系统性能 -
noatime:在读文件时,禁止更新atime。写文件时,会自动将atime信息更新到inode中 -
nodiratime:读文件时不更新所在目录的atime- 使用
noatime时将隐含nodiratime,所以无需同时指定这两项
- 使用
-
relatime:读文件时,如果该文件目前的atime信息早于mtime/ctime(这意味着修改过内容但没有更新atime),则更新atime,且如果本次读文件时发现目前的atime距离现在已经超过24小时,则也立即更新atime- 当使用
defaults挂载选项时,默认将使用relatime选项。defaults挂载选项表示使用内核的默认值,而内核中对atime的更新行为默认是relatime
- 当使用
-
lazytime:这是Kernel 4.0才支持的atime更新策略,该选项表示只在内存中维护inode中的atime/mtime和ctime信息,当遇到如下情况时才将inode中的时间戳更新到磁盘上:- (1).当inode中和时间戳无关的信息需要更新时(比如文件大小、文件权限),会顺便把时间戳信息也更新到磁盘(因为会更新整个inode)
- (2).发生sync类操作时
- (3).从内存中驱逐未被删除的inode时
- (4).内存中的atime距离现在已经超出24小时
lazytime不是独立使用的选项,它可以结合前面的几种atime更新选项,默认它结合的是relatime。但即使它结合的是strictatime,所能达到的性能也至少是单个relatime选项所能达到的性能。
systemd timesyncd做时间同步
使用systemd timesyncd做时间同步
CentOS 8中已经移除了ntp和ntpdate,它们也没有集成在基础包中。
CentOS 8使用chronyd作为时间服务器,但如果只是简单做时间同步,可直接使用systemd.timesyncd组件。
timesyncd虽然没有chronyd更健壮,但胜在简单方便,只需配置一项配置文件并执行一个命令启动便可定时同步。
$ vim /etc/systemd/timesyncd.conf
[Time]
NTP=ntp1.aliyun.com ntp2.aliyun.com
# 以下四项均可省略
FallbackNTP=1.cn.pool.ntp.org 2.cn.pool.ntp.org
RootDistanceMaxSec=5
PollIntervalMinSec=32
PollIntervalMaxSec=2048
其它常用的网络时间服务器:
cn.pool.ntp.org
1.cn.pool.ntp.org
2.cn.pool.ntp.org
3.cn.pool.ntp.org
0.cn.pool.ntp.org
ntp1.aliyun.com
ntp2.aliyun.com
ntp3.aliyun.com
ntp4.aliyun.com
ntp5.aliyun.com
ntp6.aliyun.com
ntp7.aliyun.com
配置好timesyncd.conf后,启动systemd timesyncd时间同步服务:
$ timedatectl set-ntp true
查看同步状态:
$ timedatectl status
Local time: Sat 2020-07-04 20:01:41 CST
Universal time: Sat 2020-07-04 12:01:41 UTC
RTC time: Sat 2020-07-04 20:01:40
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: yes
NTP service: inactive
RTC in local TZ: no
# 或者
$ timedatectl show
Timezone=Asia/Shanghai
LocalRTC=no
CanNTP=yes
NTP=no
NTPSynchronized=yes
TimeUSec=Sat 2020-07-04 20:01:41 CST
RTCTimeUSec=Sun 2020-07-05 04:01:40 CST
systemd timer:取代cron和at的定时任务
systemd timer:取代cron和at的定时任务
cron和systemd timer实现定时任务的比较
Linux环境下,cron是使用最广泛的定时任务工具,但它有一些不方便的地方。比如它默认:
- 只支持分钟级别精度的定时任务
- 定时规则太死板
- 当调度到本次任务时,如果上次调度的任务仍在执行,无法阻止本次任务重复执行(需结合flock)
- 无法对定时任务可能消耗的大量资源做出限制
- 不支持只执行一次的定时点的计划任务
- 日志不直观,不方便调试任务
因为cron不原生支持以上功能,所以当有以上相关需求时,只能在要调度的命令层次上寻找解决方案。
systemd系统中包含了timer计时器组件,timer可以完全替代cron+at,它具有以下特性:
- 可精确到微妙级别,其支持的时间单位包括:
- us(微秒)、ms(毫秒)、s(秒)、m(分)、h(时)、d(日)、w(周)
- 类似cron定义时间的方式(某年某月某日某时某分某秒以及时间段)
- 可对定时任务做资源限制
- 可替代cron和at工具,且支持比cron更加灵活丰富的定时规则
- 不会重复执行定时任务
- 如果触发定时任务时发现上次触发的任务还未执行完,那么本次触发的任务不会执行
- 而且systemd启动服务的操作具有幂等性,如果服务正在运行,启动操作将不做任何事,所以,甚至可以疯狂到每秒或每几秒启动一次服务,免去判断进程是否存在的过程
- 集成到journal日志,方便调试任务,方便查看任务调度情况
- …
但systemd timer相比cron也有不足支持:
- 定义定时任务的步骤稍微多一些,甚至要求用户对systemd有基本的掌握,所以使用它会有一些门槛
- cron中MAILTO环境变量可以非常方便地将所有输出或有标准错误输出时通过邮件发送给管理员,但是systemd timer没有原生支持发送邮件的功能,虽然借助一些额外的配置也能实现邮件发送,但步骤稍多
systemd timer入门示例:每3秒运行一次
使用systemd timer定时任务时,需要同时编写两个文件:
- 编写一个以
.timer为后缀的Systemd Unit,该文件描述定时任务如何定时 - 编写一个以
.service为后缀的Systemd Service Unit,该文件描述定时任务要执行的操作
这两个文件名称通常保持一致(除了后缀部分),它们可以放在:

例如:
/usr/lib/systemd/system/foo.service
/usr/lib/systemd/system/foo.timer
/etc/systemd/system/foo.service
/etc/systemd/system/foo.timer
~/.config/systemd/user/foo.timer
~/.config/systemd/user/foo.service
假设定义一个每3秒执行一次的任务,该任务用于检测页面是否正常,对应命令为curl -s -o /dev/null -w '%{http_code}' https://www.junmajinlong.com',其结果为访问页面时响应的HTTP状态码。
先编写对应服务配置文件:
$ cat /usr/lib/systemd/system/page_test.service
[Unit]
Description = "test page: https://www.junmajinlong.com"
[Service]
ExecStart = /usr/bin/curl -s -o /dev/null -w '%{http_code}' 'https://www.junmajinlong.com'
因为命令每次调用都只执行一次且快速退出,所以Service中使用了默认的Type=simple。当然,也可以使用Type=oneshot。
再编写定时器配置文件:
$ cat /usr/lib/systemd/system/page_test.timer
[Unit]
Description = "test page: https://www.junmajinlong.com every 3 seconds"
[Timer]
OnActiveSec = 1s
OnUnitInactiveSec = 3s
AccuracySec = 1us
RandomizedDelaySec = 0
[Install]
WantedBy = timers.target
再执行如下命令即可让定时器生效:
systemctl daemon-reload
systemctl start page_test.timer # 启动定时器
显然,还支持如下命令来管理定时器:
systemctl status xxx.timer
systemctl stop xxx.timer
systemctl restart xxx.timer
# 和WantedBy的值有关,若WantedBy=timers.target,则本命令多余
systemctl enable xxx.timer
回头来分析一下定时器配置文件中涉及到的指令。
首先是该文件[Install]段中的最后一行WantedBy=timers.target,它表示在开机时会自动启动该定时器,之所以会开机自动执行这些timers定时计划,是因为在basic.target中定义了timer.target依赖。
$ systemctl list-dependencies --reverse timers.target | head -2
timers.target
● └─basic.target
再看Timer段中定义定时器属性的指令。
OnActiveSec表示从该定时器启动(即systemctl start xxx.timer)之后,多长时间触发定时器对应的任务,即执行对应的Service服务。本例是启动定时器后1秒,开始第一次执行任务单元page_test.service。
OnUnitInactiveSec表示从上一次任务单元退出后,多长时间再次触发定时器对应的任务。比如在本例中,表示的含义是每次page_test.service执行完成(即页面检测完成后退出)后3秒,再次触发该任务。
剩余两个指令AccuracySec和RandomizedDelaySec,稍后再详细解释。因为在解释它们之前,需要学会观察定时任务的执行情况。
观察定时任务的执行时间点
使用systemctl list-timers可以列出当前已经生效的定时器(即如果不停止它,则迟早会触发对应的定时任务)。它会按照下次要执行的时间点先后进行排序,最快要执行的任务在最前面。
$ systemctl list-timers --no-pager
NEXT LEFT LAST PASSED UNIT ACTIVATES
Sat 2020-07-04 18:43:34 CST 20s ago Sat 2020-07-04 18:43:34 CST 20s ago page_test.timer page_test.service
Sun 2020-07-05 07:03:39 CST 12h left Fri 2020-07-03 17:27:44 CST 1 day 1h ago systemd-tmpfiles-clean.timer systemd-tmpfiles-clean.service
其中:
NEXT表示下一次要触发定时任务的时间点LEFT表示现在距离下次执行任务还剩多长时间(已经确定了下一次执行的时间点),或者显示最近一次执行任务已经过去了多长时间(还不确定下一次执行的时间点),稍后解释了AccuracySec和RandomizedDelaySec就知道为什么会有这两种表示方式LAST表示上次触发定时任务的时间点PASSED表示距离上一次执行任务已经过去多久UNIT表示是哪个定时器ACTIVATES表示该定时器所触发的任务
虽然上面的含义都比较清晰,但是想要理解透彻,还真不容易。
不过,还有其它观察定时任务执行情况的方式。由于systemd service默认集成了journald日志系统,命令的标准输出和标准错误都会输出到journal日志中。
比如,可以使用systemctl status xxx.service观察定时器对应任务的执行状况,即每次执行任务的时间点以及定时任务执行过程中的标准输出、标准错误信息。
$ systemctl status page_test.service # 注意是.service不是.timer
● page_test.service - "test page: https://www.junmajinlong.com"
Loaded: loaded
Active: inactive (dead) since Sat 2020-07-04 18:36:56 CST; 2s ago
Process: 22316 ExecStart=/usr/bin/curl ... (code=exited, status=0/SUCCESS)
Main PID: 22316 (code=exited, status=0/SUCCESS)
Jul 04 18:36:54 host.junmajinlong.com systemd[1]: Started "test page:....
Jul 04 18:36:56 host.junmajinlong.com curl[22316]: 200
Hint: Some lines were ellipsized, use -l to show in full.
上面的结果表明,最近一次test_page定时任务是在18:36:54开始执行的,18:36:56执行完成并返回执行结果,即HTTP响应状态码200,这个200是来自于curl的输出。
还可以使用journalctl工具来查看定时任务的日志信息:
# 查看指定服务的所有journal日志信息
# xxx.service是定时任务的名称
journalctl -u xxx.service
# 实时监控尾部日志,类似tail -f
journalctl -f -u xxx.service
# 显示指定时间段内的日志
# --since:从指定时间点内开始的日志
# --until:到指定时间点为止的日志
journalctl -u xxx.service --since="2020-07-04 19:06:23"
journalctl -u xxx.service --since="60s ago"
journalctl -u xxx.service --since="1min ago"
journalctl -u page_test.service --since="-60s"
例如:
$ journalctl -u page_test.service --since="-30s"
-- Logs begin at Tue 2020-06-30 14:34:48 CST, end at Sat 2020-07-04 19:13:57 CST. --
Jul 04 19:13:32 host.junmajinlong.com curl[23592]: 200
Jul 04 19:13:35 host.junmajinlong.com systemd[1]: Started "test page: https://www.junmajinlong.com".
Jul 04 19:13:43 host.junmajinlong.com curl[23602]: 200
Jul 04 19:13:46 host.junmajinlong.com systemd[1]: Started "test page: https://www.junmajinlong.com".
Jul 04 19:13:57 host.junmajinlong.com curl[23605]: 200
从结果可以看出,在19:13:35、19:13:46都执行了page_test任务。
精确触发任务:理解AccuracySec和RandomizedDelaySec
AccuracySec表示任务推迟执行的延迟范围,即从每次指定要执行任务的精确时间点到延迟时间段内的一个随机时间点启动任务。使用这种延迟,主要是为了避免systemd频繁触发定时器事件从而频繁唤醒CPU,从而让一定时间段内附近的定时任务可以集中在这个时间段内启动。

例如:
# 定时器启动后,再过10分钟第一次触发定时任务
OnActiveSec=10m
# 每次执行完任务后,再过15分钟后再次触发定时任务
OnUnitInactiveSec=15m
# 触发事件后,允许推迟0-10分钟再执行被触发的任务
AccuracySec=10m
所以,以上指令的效果是:
- 启动定时器后的10m-20m内的任一时间点触发第一次定时任务
- 之后每隔15m-25m再次触发定时任务
AccuracySec的默认值为1分钟,所以如果不定义AccuracySec的话,即使用户期待的是每秒触发一次定时任务,但事实却是会在1s-61s时间段内的一个随机时间点触发一次定时任务。(可以自己去观察一下定时任务执行情况)
但是,触发定时任务的时间点并不表示这是执行任务的时间点。触发了定时任务,还需要根据RandomizedDelaySec的值来决定何时执行定时任务。
RandomizedDelaySec指定触发定时任务后还需延迟一个指定范围内的随机时长才执行任务。该指令默认值为0,表示触发后立即执行任务。
使用RandomizedDelaySec,主要是为了在一个时间范围内分散大量被同时触发的定时任务,从而避免这些定时任务集中在同一时间点执行而CPU争抢。
可见,AccuracySec和RandomizedDelaySec的目的是相反的:
- 前者让指定范围内的定时器集中在同一个时间点一次性触发它们的定时任务
- 后者让触发的、将要被执行的任务均匀分散在一个时间段范围内
根据以上描述,如果用户想要让定时任务非常精确度地执行,需要将它们设置的足够小。例如:
AccuracySec = 1ms # 定时器到点就触发定时任务
RandomizedDelaySec = 0 # 定时任务一触发就立刻执行任务
systemd timer支持的单调定时规则
除了上面介绍的两个OnxxxSec类定时规则外,systemd timer还支持几种其它的定时器规则。
| 定时器指令 | 含义 |
|---|---|
| OnBootSec | 从开机启动后,即从内核开始运行算起,多长时间触发定时器对应任务 |
| OnStartupSec | 从systemd启动后,即内核启动init进程算起,多长时间触发定时器对应任务 |
| OnActiveSec | 从该定时器启动后,多长时间触发定时器对应的任务 |
| OnUnitInactiveSec | 从上次任务单元退出后,多长时间再次触发定时器对应的任务 |
| OnUnitActiveSec | 从上次触发的任务开始执行(状态达到active)算起,多长时间再次触发定时器对应的任务 注:(1)当Service文件中Type=oneshot,这类任务不会出现active状态,除非配置了RemainAfterExit指令(参考 man systemd.service)(2)这个定时器用的不如OnUnitInactiveSec多,因为这个定时器是以启动时间为基准的,有可能下次触发任务时,上次任务还没有执行完成,systemd会忽略下次任务 |
其中OnBootSec和OnStartupSec比较特殊,因为定时器自身的启动比这两个时间点要晚,如果定时器配置文件中以这两个指令为定时任务的触发基准,可能会出现超期现象。比如某定时器设置OnBootSec=1s,但如果从启动内核到启动定时器已经过了2s,那么这个定时任务就超期了。好在,systemd会对这两个特殊的指令特殊对待,如果这类定时任务超期了,将立即执行定时任务实现补救。
但对其它三个指令定义的定时器,超期了就超期了,不会再尝试去补救。
也就是说,即使过了有效期,这两类定时任务还是有效的,而其它定时任务则失效。
事实上,这几个定时器指令都是单调定时器,即:这些任务的触发时机,总是以某个时间点为基准单调增加的。
更为灵活的定时规则:OnCalendar
cron定时任务支持* * * * *来定义定时任务,这5个位置分别表示分 时 日 月 周。
前面已经介绍的systemd timer的定时规则已经能够实现只执行一次和每隔多久执行一次的定时规则。下面要介绍的OnCalendar基于日历的定时规则完全可以胜任cron的定时规则。
例如:
OnCalendar = Thu,Fri 2012-*-1,5 11:12:13
这表示2012年每个月的1或5号的11点12分13秒,同时要求是周四或周五。
OnCalendar支持的时间格式很灵活,所以下面介绍它的内容也稍多,请慢慢享用。
systemd timer可识别的时间单位包括以下几种:
- 微秒级单位:usec, us, µs
- 毫秒级单位:msec, ms
- 秒级单位(省略单位时的默认单位):seconds, second, sec, s
- 分钟级单位:minutes, minute, min, m
- 小时级单位:hours, hour, hr, h
- 天的单位:days, day, d
- 周的单位:weeks, week, w
- 使用周单位时,必须使用三字母表示法或英文全称,如Fri、Sun、Monday
- 月的单位:months, month, M
- 年的单位(一年以365.25天算):years, year, y
多个时间单位可结合使用,且时间的出现顺序无关。
例如下面的时间单位都是有效的:
2 h --> 2小时
2hours --> 2小时
48hr --> 48小时
1y 12month --> 1年12个月,即2年
55s500ms --> 55秒+500毫秒
300ms20s 5day --> 5天+20秒+300毫秒,顺序无关
在定时器里,还会经常用到表示某年某月某日、某时某分某秒的时间戳格式。systemd内部的标准时间戳格式为:
Fri 2012-11-23 11:12:13
Fri 2012-11-23 11:12:13 UTC
对于时区而言,如果要加时区,则必须只能加UTC三个字符,否则只能省略,此时表示本地时区(注:此处表述是不对的,因为还支持其他更复杂的格式,但时区相关的内容太多,这里略去)。
最前面的周几可以省略,如非需要周几符号,强烈建议省略它。但如果不省略,则必须只能使用三字母表示法或英文全称,即合理的周几符号包括:
Monday Mon
Tuesday Tue
Wednesday Wed
Thursday Thu
Friday Fri
Saturday Sat
Sunday Sun
年-月-日与时:分:秒二者可省其一,但不可全省。若省前者,则表示使用当前日期,若省后者则表示使用00:00:00。
时:分:秒可以省略:秒,相当于使用:00。
年-月-日中的年可以省略为2位数字表示,相当于20xx,但强烈建议不要使用这种方式。
如果指定的星期与年-月-日(即使此部分已被省略)与实际不相符,那么该时间戳无效。
还可以使用一些时间戳关键字:now,today,yesterday,tomorrow。
还可以使用一些相对时间表示法:时长加上+前缀或者' left'后缀(注意有空格),表示以此时间为基准向未来前进指定的时长,时长加上-前缀或者' ago'后缀(注意有空格),表示以此时间为基准向过去倒退指定的时长。
最后,时长加上@前缀表示相对于UNIX时间原点(1970-01-01 00:00:00 UTC)之后多长时间。
以下都是有效时间:
# 假如今日是2012-11-23
Fri 2012-11-23 11:12:13 → Fri 2012-11-23 11:12:13
2012-11-23 11:12:13 → Fri 2012-11-23 11:12:13
2012-11-23 11:12:13 UTC → Fri 2012-11-23 19:12:13
2012-11-23 → Fri 2012-11-23 00:00:00
12-11-23 → Fri 2012-11-23 00:00:00
11:12:13 → Fri 2012-11-23 11:12:13
11:12 → Fri 2012-11-23 11:12:00
now → Fri 2012-11-23 18:15:22
today → Fri 2012-11-23 00:00:00
today UTC → Fri 2012-11-23 16:00:00
yesterday → Fri 2012-11-22 00:00:00
tomorrow → Fri 2012-11-24 00:00:00
+3h30min → Fri 2012-11-23 21:45:22
-5s → Fri 2012-11-23 18:15:17
11min ago → Fri 2012-11-23 18:04:22
2 months 5 days ago
@1395716396 → Tue 2014-03-25 03:59:56
OnCalendar指令使用基于日历的定时规则,基于日历的格式是对systemd标准时间戳的扩展:在标准时间戳的基础上,可以使用一些额外的语法。
这些额外的语法包括:
- 可使用
,列出离散值,可使用..表示一个范围 - 对于
年-月-日和时:分:秒这两部分的每个子部分:- 可使用
*表示匹配任意值 - 可使用
/N(N是整数)后缀表示每隔N个单位,特别地/1表示每次增加一个单位
- 可使用
- 对于
年-月-日部分,可使用月~日替代月-日表示一个月中的倒数第N天 - 对于
秒,可使用小数表示更高精度,最高精度为6位小数 - 还支持如下表示:
- minutely:每分钟
- hourly:每小时
- daily:每天
- monthly:每月
- weekly:每周
- yearly:每年
- quarterly:每季度
- semiannually:每半年
例如:
Sat,Mon..Wed -> 周一、二、三、四
*:00 -> 每小时,省略秒位
*:* -> 每分钟,省略秒位
*:*:* -> 每秒
*-*-01 00:00 -> 每月一号,省略秒位
*-02~03 -> 表示2月的倒数第三天
*-05~07/1 -> 表示5月最后7天中的每一天
*-05~1..7 -> 同上
Mon *-05~07/1 -> 表示5月最后一个星期一
*:*:3.33/10.05 -> 小数表示秒。3.33,13.38,23.43,33.48,43.53
9..17/2:00 -> 从上午9点开始每隔两小时,直到下午5点
12..14:10,20 -> 12到14点的第10分钟和第20分钟,即1[234]:[12]0:00
当不明确一个基于日历表示法的时间时,可使用神器systemd-analyize calendar命令来分析(早期systemd版本不支持calendar子命令)。
例如:
$ systemd-analyze calendar Sat,Mon..Wed
Original form: Sat,Mon..Wed
Normalized form: Mon..Wed,Sat *-*-* 00:00:00
Next elapse: Mon 2020-07-06 00:00:00 CST
(in UTC): Sun 2020-07-05 16:00:00 UTC
From now: 18h left
$ systemd-analyze calendar "*-05~07/1"
Original form: *-05~07/1
Normalized form: *-05~07/1 00:00:00
Next elapse: Tue 2021-05-25 00:00:00 CST
(in UTC): Mon 2021-05-24 16:00:00 UTC
From now: 10 months 19 days left
$ systemd-analyze calendar "Mon *-05~07/1"
Original form: Mon *-05~07/1
Normalized form: Mon *-05~07/1 00:00:00
Next elapse: Mon 2021-05-31 00:00:00 CST
(in UTC): Sun 2021-05-30 16:00:00 UTC
From now: 10 months 25 days left
请分析man systemd.time中给出的以下示例:
Sat,Thu,Mon..Wed,Sat..Sun → Mon..Thu,Sat,Sun *-*-* 00:00:00
Mon,Sun 12-*-* 2,1:23 → Mon,Sun 2012-*-* 01,02:23:00
Wed *-1 → Wed *-*-01 00:00:00
Wed..Wed,Wed *-1 → Wed *-*-01 00:00:00
Wed, 17:48 → Wed *-*-* 17:48:00
Wed..Sat,Tue 12-10-15 1:2:3 → Tue..Sat 2012-10-15 01:02:03
*-*-7 0:0:0 → *-*-07 00:00:00
10-15 → *-10-15 00:00:00
monday *-12-* 17:00 → Mon *-12-* 17:00:00
Mon,Fri *-*-3,1,2 *:30:45 → Mon,Fri *-*-01,02,03 *:30:45
12,14,13,12:20,10,30 → *-*-* 12,13,14:10,20,30:00
12..14:10,20,30 → *-*-* 12..14:10,20,30:00
mon,fri *-1/2-1,3 *:30:45 → Mon,Fri *-01/2-01,03 *:30:45
03-05 08:05:40 → *-03-05 08:05:40
08:05:40 → *-*-* 08:05:40
05:40 → *-*-* 05:40:00
Sat,Sun 12-05 08:05:40 → Sat,Sun *-12-05 08:05:40
Sat,Sun 08:05:40 → Sat,Sun *-*-* 08:05:40
2003-03-05 05:40 → 2003-03-05 05:40:00
05:40:23.4200004/3.1700005 → *-*-* 05:40:23.420000/3.170001
2003-02..04-05 → 2003-02..04-05 00:00:00
2003-03-05 05:40 UTC → 2003-03-05 05:40:00 UTC
2003-03-05 → 2003-03-05 00:00:00
03-05 → *-03-05 00:00:00
hourly → *-*-* *:00:00
daily → *-*-* 00:00:00
daily UTC → *-*-* 00:00:00 UTC
monthly → *-*-01 00:00:00
weekly → Mon *-*-* 00:00:00
weekly Pacific/Auckland → Mon *-*-* 00:00:00 Pacific/Auckland
yearly → *-01-01 00:00:00
annually → *-01-01 00:00:00
*:2/3 → *-*-* *:02/3:00
其它选项:Unit和Persistent
[Timer]段中还可以使用Unit指令和Persistent指令。
Unit=xxx.service:默认情况下,a.timer对应要执行的任务文件是a.service,使用Unit指令可以明确指定触发定时任务事件时要执行的文件Persistent=yes/no:只在使用了OnCalendar时有效,默认值no。设置yes时,会将上次执行任务的时间点保存在磁盘上,使得定时器再次被启动时,可以立即判断是否要执行丢失的任务- 以空文件方式保存,以该空文件的atime/mtime/ctime信息记录执行任务的时间点
- 文件保存路径:
/var/lib/systemd/timers,或~/.local/share/systemd/(用户级定时器保存路径) - 可删除这些时间戳文件,使得不会立即触发丢失的任务
比如下面的定时任务表示每天凌晨执行任务。
OnCalendar = 00:00
Persistent = yes
因为使用了Persistent,所以每次执行完任务后都会将本次执行的时间点记录在磁盘文件中,如果在23:59:50时遇到一次重启耽搁1分钟,那么在重启成功后会立即执行该任务。如果Persistent=no,则在重启后不会立即执行任务,而是等到下一个凌晨才执行任务。
systemd timer定义用户级定时任务
用户级定时器在用户登录后开始启动,用户退出时(所有使用该用户启动的终端的会话都断开)停止。
用户级定时器要求将.timer和对应的.service定义在~/.config/systemd/user/目录下。如果使用了OnCalendar和Persisten指令,时间戳文件保存在~/.local/share/systemd/目录下。
例如:
$ mkdir -p ~/.config/systemd/user
$ cat ~/.config/systemd/user/test.service
[Unit]
Description = current time when task is been executed
[Service]
ExecStart = /bin/bash -c '/usr/bin/date +"%%T" >>/tmp/a.log'
$ cat ~/.config/systemd/user/test.timer
[Unit]
Description = user login timer
[Timer]
AccuracySec = 1ms
RandomizedDelaySec = 0
OnCalendar = *:*:*
[Install]
WantedBy = timer.target
再启动用户定时器:
systemctl --user daemon-reload
systemctl --user start test.timer
systemctl --user list-timers
查看定时器触发的任务状态:
systemctl --user status test.service
停止定时器:
systemctl --user stop test.timer
systemd临时定时任务
systemd-run命令支持定时器类选项,所以通过systemd-run可以启动临时的定时任务。
systemd-run支持的定时器选项有:
- –on-boot
- –on-startup
- –on-unit-active
- –on-unit-inactive
- –on-active
- –on-calendar
此外还支持--timer-property选项定义[Timer]中的指令。
例如:
# 执行完该命令后,再过30秒执行touch,不精确触发
$ systemd-run --on-active=30 /bin/touch /tmp/foo
# 执行完该命令后,每两秒touch一次/tmp/foo,且精确触发
$ systemd-run \
--on-calendar="*:*:1/2" \
--timer-property="AccuracySec=1us" \
--timer-property="RandomizedDelaySec=0" \
/bin/touch /tmp/foo
Running timer as unit: run-r5eda49cf458447f38a7d48a2ab0f33c6.timer
Will run service as unit: run-r5eda49cf458447f38a7d48a2ab0f33c6.service
执行完成后,会报告所执行的timer unit和service unit,可通过这个值来查看状态或管理它们。例如,停止这个临时定时器:
$ systemctl stop run-r5eda49cf458447f38a7d48a2ab0f33c6.timer
限制定时任务的资源使用量
有些定时任务可能会消耗大量资源,比如执行rsync的定时任务、执行数据库备份的定时任务,等等,它们可能会消耗网络带宽,消耗IO带宽,消耗CPU等资源。
想要控制这些定时任务的资源使用量也非常简单,因为真正执行任务的是.service,而Service配置文件中可以轻松地配置一些资源控制指令或直接使用Slice定义的CGroup。这些资源控制类的指令可参考man systemd.resource-control。
例如,直接在[Service]中定义资源控制指令:
[Service]
Type=simple
MemoryLimit=20M
ExecStart=/usr/bin/backup.sh
又或者让Service使用定义好的Slice:
[Service]
ExecStart=/usr/bin/backup.sh
Slice=backup.slice
其中backup.slice的内容为:
$ cat /usr/lib/systemd/system/backup.slice
[Unit]
Description=Limited resources Slice
DefaultDependencies=no
Before=slices.target
[Slice]
CPUQuota=50%
MemoryLimit=20M
systemd path:实时监控文件和目录的变动
systemd path:实时监控文件和目录的变动
systemd path工具提供了监控文件、目录变化并触发执行指定操作的功能。
有时候这种监控功能是非常实用的,比如监控到/etc/nginx/nginx.conf或/etc/nginx/conf.d/发生变化后,立即reload nginx。虽然,用户也可以使用inotify类的工具来监控,但远不如systemd path更方便、更简单且更易于观察监控效果和调试。
其实,systemd path的底层使用的是inotify,所以受限于inotify的缺陷,systemd path只能监控本地文件系统,而无法监控网络文件系统。
systemd path能监控哪些操作
systemd path暴露的监控功能并不多,它能监控的动作包括:
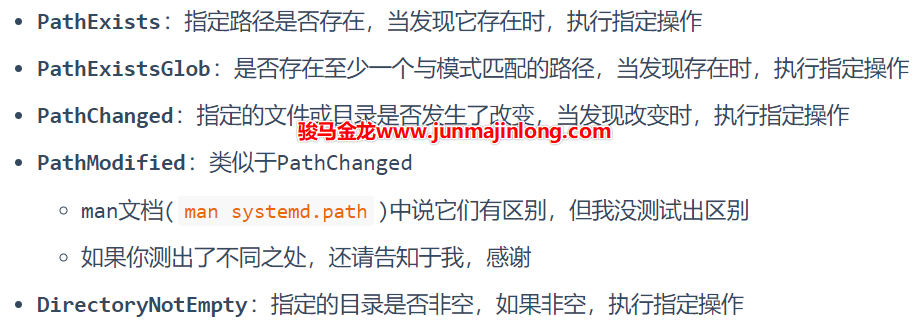
这些指令监控的路径必须是绝对路径。
可以多次使用这些指令,且同一个指令也可以使用多次,这样就能够同时监控多个文件或目录,它们将共用事件触发后执行的操作。如果想要对不同监控目录执行不同操作,那只能定义多个systemd path的监控实例。
如果监控某路径时发现权限不足,则一直等待,直到有权监控。
如果在启动Path Unit时(systemctl start xxx.path),指定的路径已经存在(对于PathExists与PathExistsGlob来说)或者指定的目录非空(对于DirectoryNotEmpty来说),将会立即触发并执行对应操作。不过,对于PathChanged与PathModified来说,并不遵守这个规则。
systemd path使用示例
要使用systemd path的功能,需至少编写两个文件,一个.path文件和一个.service文件,这两个文件的前缀名称通常保持一致,但并非必须。这两个文件可以位于以下路径:
- /usr/lib/systemd/system/
- /etc/systemd/system/
- ~/.config/systemd/user/:用户级监控,只在该用户登录后才监控,该用户所有会话都退出后停止监控
例如:
/usr/lib/systemd/system/test.path
/usr/lib/systemd/system/test.service
/etc/systemd/system/test.path
/etc/systemd/system/test.service
~/.config/systemd/user/test.path
~/.config/systemd/user/test.service
例如,有以下监控需求:
- 监控/tmp/foo目录下的所有文件修改、创建、删除等操作
- 如果被监控目录/tmp/foo不存在,则创建
- 监控/tmp/a.log文件的更改
- 监控/tmp/file.lock锁文件是否存在
为了简化,这些监控触发的事件都执行同一个操作:向/tmp/path.log中写入一行信息。
此处将path_test.path文件和path_test.service文件放在/etc/systemd/system/目录下。
path_test.path内容如下:
$ cat /etc/systemd/system/path_test.path
[Unit]
Description = monitor some files
[Path]
PathChanged = /tmp/foo
PathModified = /tmp/a.log
PathExists = /tmp/file.lock
MakeDirectory = yes
Unit = path_test.service
# 如果不需要开机后就自动启动监控的话,可省略下面这段
# 如果开机就监控,则加上这段,并执行systemctl enable path_test.path
[Install]
WantedBy = multi-user.target
其中MakeDirectory指令默认为no,当设置为yes时表示如果监控的目录不存在,则自动创建目录,但该指令对PathExists指令无效。
Unit指令表示该sysmted path实例监控到符合条件的事件时启动的服务单元,即要执行的对应操作。通常省略该指令,这时启动的服务名称和path实例的名称一致(除了后缀),例如path_test.path默认启动的是path_test.service服务。
path_test.service内容如下:
$ cat /etc/systemd/system/path_test.service
[Unit]
Description = path_test.service
[Service]
ExecStart = /bin/bash -c 'echo file changed >>/tmp/path.log'
然后执行如下操作启动该systemd path实例:
systemctl daemon-reload
systemctl start path_test.path
使用如下命令可以列出当前已启动的所有systemd path实例:
$ systemctl --type=path list-units --no-pager
UNIT LOAD ACTIVE SUB DESCRIPTION
systemd-ask-password-console.path loaded active waiting Dispatch Password Requests to Console
systemd-ask-password-wall.path loaded active waiting Forward Password Requests to Wall Dir
path_test.path loaded active waiting monitor some files
然后测试该systemd path能否如愿工作。
$ touch /tmp/foo/a
$ touch /tmp/foo/a
$ touch /tmp/a.log
$ echo 'hello world' >>/tmp/a.log
$ rm -rf /tmp/a.log
...
如果想观察触发情况,可使用journalctl。例如:
$ journalctl -u path_test.service
Jul 05 16:09:43 junmajinlong.com systemd[1]: Started path_test.service.
Jul 05 16:09:45 junmajinlong.com systemd[1]: Started path_test.service.
Jul 05 16:09:47 junmajinlong.com systemd[1]: Started path_test.service.
Jul 05 16:09:49 junmajinlong.com systemd[1]: Started path_test.service.
Jul 05 16:09:51 junmajinlong.com systemd[1]: Started path_test.service.
Jul 05 16:09:55 junmajinlong.com systemd[1]: Started path_test.service.
systemd path临时监控
使用systemd-run命令可以临时监控路径。
$ systemd-run --path-property=PathModified=/tmp/b.log echo 'file changed'
Running path as unit: run-rb6f67e732fb243c7b530673cac867582.path
Will run service as unit: run-rb6f67e732fb243c7b530673cac867582.service
可以查看当前已启动的systemd path实例,包括临时监控实例:
$ systemctl --type=path list-units --no-pager
如果需要停止,使用run-xxxxxx名称即可:
systemctl stop run-rb6f67e732fb243c7b530673cac867582.path
systemd path资源控制
systemd path触发的任务可能会消耗大量资源,比如执行rsync的定时任务、执行数据库备份的定时任务,等等,它们可能会消耗网络带宽,消耗IO带宽,消耗CPU等资源。
想要控制这些定时任务的资源使用量也非常简单,因为真正执行任务的是.service,而Service配置文件中可以轻松地配置一些资源控制指令或直接使用Slice定义的CGroup。这些资源控制类的指令可参考man systemd.resource-control。
例如,直接在[Service]中定义资源控制指令:
[Service]
Type=simple
MemoryLimit=20M
ExecStart=/usr/bin/backup.sh
又或者让Service使用定义好的Slice:
[Service]
ExecStart=/usr/bin/backup.sh
Slice=backup.slice
其中backup.slice的内容为:
$ cat /usr/lib/systemd/system/backup.slice
[Unit]
Description=Limited resources Slice
DefaultDependencies=no
Before=slices.target
[Slice]
CPUQuota=50%
MemoryLimit=20M
systemd path的【Bug】
systemd path监控路径上所产生的事件是需要时间的,如果两个事件发生时的时间间隔太短,systemd path可能会丢失第二个甚至后续第三个第四个等等事件。
例如,使用PathChanged或PathModified监控路径/tmp/foo目录时,执行以下操作触发事件:
$ touch /tmp/foo/a && rm -rf /tmp/foo/a
期待的是systemd path能够捕获这两个事件并执行两次对应的操作,但实际上只会执行一次对应操作。换句话说,systemd path丢失了一次事件。
之所以会丢失事件,是因为touch产生的事件被systemd path捕获,systemd path立即启动对应.service服务做出对应操作,在本次操作还未执行完时,rm又立即产生了新的事件,于是systemd path再次启动服务,但此时服务尚未退出,所以本次启动服务实际上什么事也不做。
所以,从结果上看去就像是systemd path丢失了事件,但实际上是因为服务尚未退出的情况下再次启动服务不会做任何事情。
可以加上一点休眠时间来耽搁一会:
$ touch /tmp/foo/a && sleep 0.1 && rm -rf /tmp/foo/a
上面的命令会成功执行两次对应操作。
再比如,将.service文件中的ExecStart设置为/usr/bin/sleep 5,那么在5秒内的所有操作,除了第一次触发的事件外,其它都会丢失。
systemd path的这个『bug』也有好处,因为可以让瞬间产生的多个有关联关系的事件只执行单次任务,从而避免了中间过程产生的事件也重复触发相关操作。
systemd时代的开机启动流程(UEFI+systemd)
计算机启动流程可以分为几个大阶段:
- 内核加载前
- 本阶段和操作系统无关,Linux或Windows或其它系统在这阶段的顺序是一样的
- 内核加载中–>内核启动完成
- 内核加载后–>系统环境初始化完成
- 终端加载、用户登录
这几个阶段中又有很多小阶段,每个阶段都各司其职。本文将主要介绍UEFI+systemd环境下的Linux系统启动流程,如果想要了解Bios+MBR+SysV环境下的详细系统启动流程(如CentOS 6),可参考我以前写的一篇非常详细的文章CentOS 6开机流程(Bios+MBR+SysV),在需要的时候,本文也会稍微介绍一些Bios+MBR+SysV的内容以作比较和整合。
开机流程图预览
下图是开机的全局流程图,具体的细节后文再详细描述。
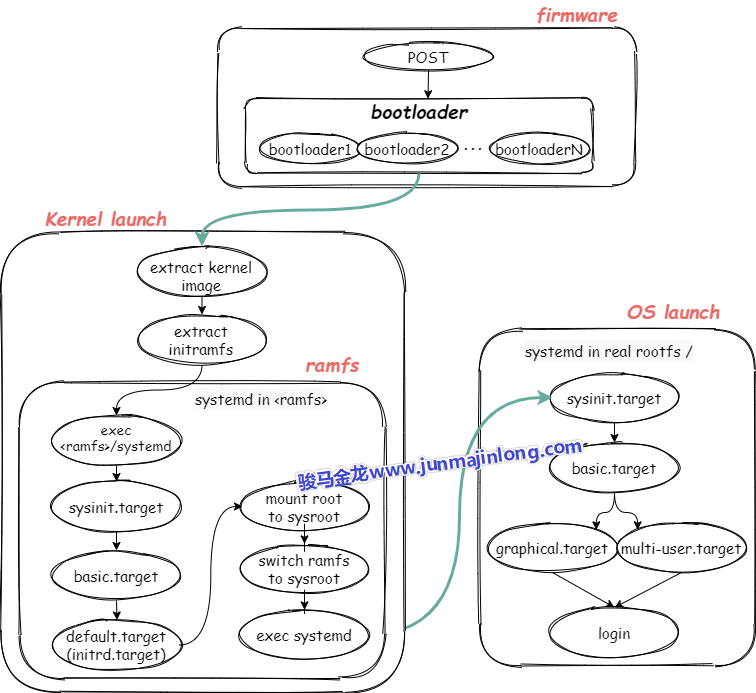
按下电源和固件阶段
按下电源,计算机开始通电,最重要的是要接通cpu的电路,然后通过cpu的针脚让cpu运行起来,只有cpu运行起来才能执行相关代码跳到第一个程序:bios或uefi上,并将CPU控制权交给bios或uefi程序。
下面不考虑从网络启动系统的方式,只考虑启动本地系统。
使用bios的固件阶段
对于BIOS来说,BIOS的工作包括:
- (1).POST,即加电对部分硬件进行检查
- (2).POST自检之后,BIOS初始化一部分启动所需的硬件(比如会启动磁盘,某些机器可能还会启动键盘)
- (3).根据启动顺序找到排在第一位的磁盘
- (4).BIOS跳转到所选择磁盘的前446字节,这446字节的代码是第一个bootloader程序,BIOS加载bootloader并将CPU控制权交给bootloader程序
- 磁盘的第一个扇区(前512字节)称为MBR,其中前446字节是bootloader程序,中间64字节是磁盘分区表,最后两个字节是固定0x55AA的魔数标记,标记该磁盘的MBR是否有效,如果无效,则读取启动顺序中的第二位磁盘
- MBR中的bootloader是硬编码在磁盘第一个扇区中的,像grub类的启动管理器会安装各个阶段的boot loader,包括这个MBR bootloader
- (5).执行MBR中的bootloader程序,这个bootloader可能会直接加载内核,也可能会跳转到更多的bootloader程序上
- 因为MBR中的bootloader只有446字节,代码量非常有限,所以有些系统会使用多段bootloader的方式。比如grub在安装MBR的时候,所安装的MBR bootloader最后的代码逻辑是跳转到下一个阶段的bootloader(也是grub安装的),如果下一个阶段的bootloader还不够,那么还可以有更多阶段的bootloader。这种模式称为链式启动
- 因为内核镜像和启动管理器配置文件等内核启动所必须的文件都在boot分区下,所以中间某个bootloader程序会加载boot分区所在文件系统驱动,使之能够识别boot分区并读取boot分区中的文件
- (6).最后一个bootloader将获取内核启动参数(比如从boot分区读取grub配置文件获取内核参数),并加载操作系统的内核镜像(grub配置文件中指定了内核镜像的路径),同时向内核传递内核启动参数,然后将CPU控制权交给内核程序
至此,内核已经加载到内存中,并进入到了内核启动阶段,CPU控制权将转移到内核,内核开始工作。
注:Bios典型支持的是MBR分区类型,但也支持GPT分区类型。UEFI典型支持的是GPT分区类型,但也支持MBR。
从系统启动的角度看,无需在乎是MBR还是GPT,其基本目的都是找到各阶段的bootloader。
使用uefi的固件阶段
UEFI支持读取分区表,也支持直接读取一个文件系统。UEFI不会启动任何MBR扇区中的bootloader(即使有安装MBR),而是从非易失性存储中找到启动条目(boot entry)并启动它。
典型的UEFI支持的非易失性存储有FAT12、FAT16和FAT32文件系统(即EFI系统分区),但是发行商也可以加入额外的文件系统,只要提供对应文件系统的驱动程序即可。比如Macs支持HFS+文件系统。此外,UEFI也支持ISO-9660光盘。
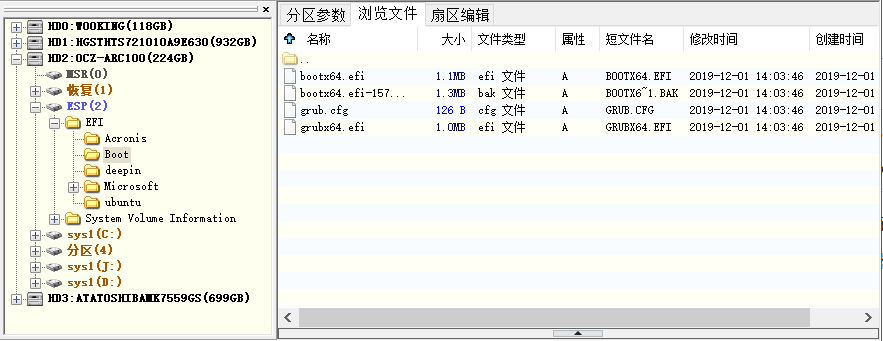
UEFI会启动EFI系统分区中的EFI程序,所谓的EFI程序即类似bootloader的程序,比如单纯的bootloader程序,类似GRUB的启动管理器、UEFI shell程序等(作为systemd系列文章之一,在此有必要一提,systemd-boot工具也可以制作基于UEFI的bootloader)。这些程序通常位于efi系统分区下的/EFI/vendor_name目录中,不同发行商可加入不同的efi程序。在EFI分区的/efi/目录下还有一个boot目录,这个目录中保存了所有的启动条目。
如下图,EFI目录下除了Boot目录外,还有4个发行商(Acronis、deepin、Microsoft、Ubuntu)各自的EFI程序目录。
当使用UEFI固件时,CPU通电后,UEFI的工作内容主要包括:

至此,内核已经加载到内存中,并进入到了内核启动阶段,CPU控制权将转移到内核,内核开始工作。
内核启动阶段
到目前为止,内核已经被加载到内存掌握了控制权,且收到了boot loader最后传递的内核启动参数,包括init ramdisk镜像的路径
但注意,所有的内核镜像都是以bzImage方式压缩过的,压缩后CentOS 6的内核大小大约为4M,CentOS 7的内核大小大约为5M,CentOS 8的内核大小约9M。所以内核要能正常运作下去,它需要进行解压释放。
# CentOS 8内核大小
$ ls -lh /boot/vmlinuz-4.18.0-193.el8.x86_64
-rwxr-xr-x. 1 root root 8.6M May 8 19:07 /boot/vmlinuz-4.18.0-193.el8.x86_64
注:谁解压内核?
内核引导协议要求bootloader最后将内核镜像读取到内存中,内核镜像是以bzImage格式被压缩。bootloader读取内核镜像到内存后,会调用内核镜像中的startup_32()函数对内核解压,也就是说,内核是自解压的。解压之后,内核被释放,开始调用另一个startup_32()函数(同名),startup32函数初始化内核启动环境,然后跳转到start_kernel()函数,内核就开始真正启动了,PID=0的0号进程也开始了……
当内核真正开始运行后,将从/boot分区找到initial ram disk image(后面简称init ramdisk)并解压。init ramdisk要么是initrd,要么是initramfs,它们可使用dracut工具生成,早期系统用initrd比较多,因为现在就会都用initramfs,所以后面可能会以initramfs来描述init ramdisk。
init ramdisk解压之后就得到了内核空间的根文件系统(这是启动过程中的早期根分区,也称为虚根)。对于使用systemd的系统来说,得到虚根之后就可以调用集成在initramfs中的systemd程序,其PID=1。从现在开始,就进入了早期的用户空间(early userspace),systemd进程可以在此时做一些内核启动剩余的必要操作。
完成内核启动的必要操作后,systemd最后会将虚根切换为真实的根分区(即系统启动后用户看到的根分区),并进入真正的用户空间阶段。systemd从此开始就成为了用户空间的总管进程,也是所有用户空间进程的祖先进程。
详细分析内核启动阶段
上面描述的内核启动过程很简单,但里面还有一些『细节』值得思考。
1.如何找到init ramdisk
实际上,内核运行后,会创建一个负责内核运行环境初始化的进程,该进程会根据boot loader传递过来的内核启动参数找到init ramdisk的路径。正常情况下,该路径在boot分区中。之所以能够读取Boot分区是因为在固件阶段,bootloader程序已经加载了boot分区的文件系统驱动。
2.为什么要用init ramdisk
因为直到现在还无法读取根分区,甚至目前还没有根分区的存在,但显然,之后是要挂载根分区的。但是要挂载根分区进而访问根分区,要求知道根分区的类型(比如是xfs还是ext4),从而装在根文件系统的驱动模块。
由于不同用户在安装操作系统时,可能会选择不同的文件系统作为根文件系统的类型,所以不同用户的操作系统在内核启动过程中,根文件系统类型是不同的。如何知道该用户所装的操作系统的根文件系统是哪种类型的?
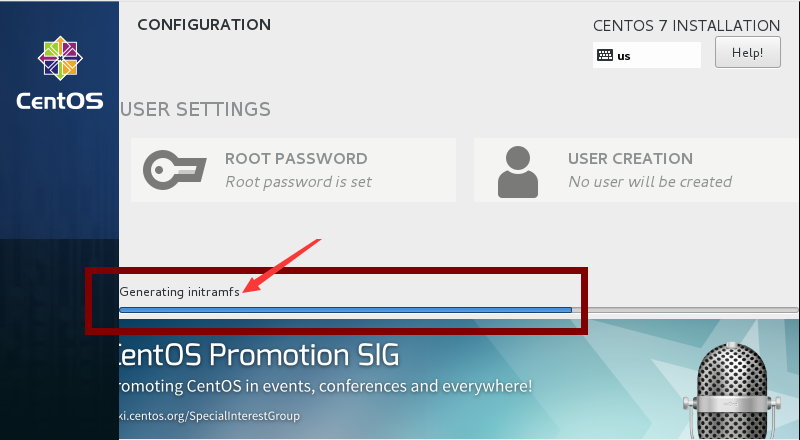
事实上,在安装操作系统的最后阶段,会自动收集当前所装操作系统的信息,并根据这些信息动态生成一些文件,包括用户所选择的根文件系统的类型以及对应的文件系统驱动模块。这个过程收集的内容会保存在init ramdisk镜像中。
如下图,是某次我安装CentOS 7过程中截取下来的生成initramfs镜像文件的图片。
3.内核中根分区的来源
内核会将init ramdisk镜像解压在一个位置下,这个位置称为rootfs,即根文件系统,这个根分区称为虚根,因为这个根分区和系统启动后用户看到的根分区不是同一个根分区。
对于使用initramfs镜像的ramdisk来说,这个rootfs即为ramfs(ram file system),它是一个在解压initramfs镜像后就存在且挂载的文件系统,但是系统启动之后用户并不能找到它,因为在内核启动完成后它就会被切换到真实的根文件系统。
用户也可以手动解压/boot/initramdisk-xxx.img镜像:
$ mkdir /tmp/hhh
$ cd /tmp/hhh
$ /usr/lib/dracut/skipcpio /boot/initramfs-$(uname -r).img | zcat | cpio -idmv
可以想象一下,init ramdisk镜像解压在/tmp/hhh目录下,那么这个目录就可以看作是在内核启动过程中的rootfs。解压得到的根目录和系统启动后的根目录内核很相似:
$ cd /tmp/hhh
$ ls
bin lib run sysroot
dev lib64 sbin tmp
etc proc shutdown usr
init root sys var
再深入一点看,会发现ramdisk中已经生成了我当前操作系统根分区和boot分区的驱动模块。
# boot分区是ext4,根分区是xfs
$ df -T
Filesystem Type ... Mounted on
...
/dev/mapper/cl-root xfs ... /
/dev/nvme0n1p1 ext4 ... /boot
# initramfs中已经具备了ext4和xfs的驱动模块
$ cd /tmp/hhh
$ tree usr/lib/modules/4.18.0-193.el8.x86_64/kernel/fs/
usr/lib/modules/4.18.0-193.el8.x86_64/kernel/fs/
├── ext4
│ └── ext4.ko.xz
├── jbd2
│ └── jbd2.ko.xz
├── mbcache.ko.xz
└── xfs
└── xfs.ko.xz
4.PID=1进程的来源
或者说,PID=1的init程序集成在init ramdisk中?在内核启动过程中就加载了它?
对于早期的initrd来说,init程序并没有集成在initrd中,所以那时的内核会在装载完根分区驱动模块后去根分区寻找/sbin/init程序并调用它。且对于使用initrd的启动过程来说,加载/sbin/init的时机比较晚,很多内核启动过程中的环境都是由内核进程而非init进程完成的。
对于initramfs,它已经将init程序集成在init ramdisk镜像文件中了。如下:
$ cd /tmp/hhh
$ ls -l
total 8
lrwxrwxrwx. ... bin -> usr/bin
drwxr-xr-x. ... dev
drwxr-xr-x. ... etc
lrwxrwxrwx. ... init -> usr/lib/systemd/systemd
lrwxrwxrwx. ... lib -> usr/lib
lrwxrwxrwx. ... lib64 -> usr/lib64
drwxr-xr-x. ... proc
drwxr-xr-x. ... root
drwxr-xr-x. ... run
lrwxrwxrwx. ... sbin -> usr/sbin
-rwxr-xr-x. ... shutdown
drwxr-xr-x. ... sys
drwxr-xr-x. ... sysroot
drwxr-xr-x. ... tmp
drwxr-xr-x. ... usr
drwxr-xr-x. ... var
仔细观察上面的文件结构。init是一个指向systmed的软链接(因为这里使用的是systemd而不是SysV),此外还有几个重要的目录proc、sys、dev、sysroot。
由于内核加载到这里已经初始化一些运行环境了,有些环境是可以保留下来的,这样系统启动后就能直接使用这些已经初始化的环境而无需再次初始化。比如内核的运行状态等参数保存在虚根的/proc和/sys(当然,内核运行环境是保存在内存中的,这两个目录只是内核暴露给用户的路径),再比如,已经收集到的硬件设备信息以及设备的运行环境也要保存下来,保存的位置是/dev。
sysroot则是最重要的,它就是系统启动后用户看到的真正的根分区。没错,真正的根分区只是ramdisk中的一个目录。
systemd在内核启动阶段做的事
在内核启动阶段,当调用了集成在initramfs中的systemd之后,systemd将接管后续的启动操作。但是在这个阶段,systemd具体会做哪些操作呢?
分析systemd在启动阶段所做的事之前,最好对启动流程中的systemd能有一个全局的了解。
注:下图适用于即将解释的内核启动阶段中systemd的流程,也适用于内核启动完成后systemd的流程。
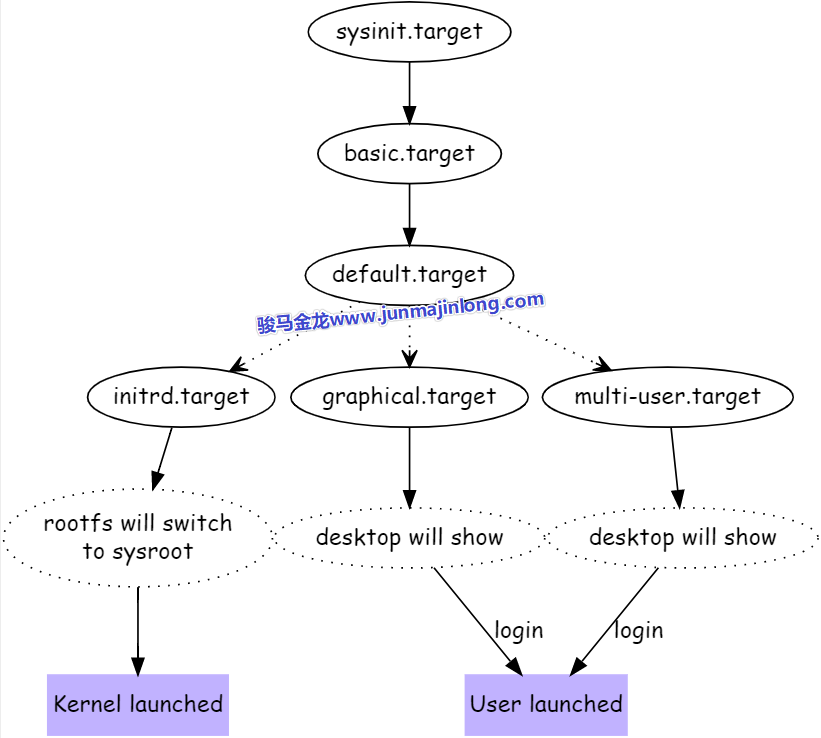
在启动过程中,systemd有几个大目标,每个目标以.target表示。systemd的target主要作用是对多个任务进行分组,比如basic.target中,可能包含了很多任务。
- 第一个大目标:sysinit.target
sysinit.target主要目的是读系统运行环境做初始化,初始化完成后进入下一个大目标 - 第二个大目标:basic.target
basic.target的作用主要是在环境初始化完成后执行一些基本任务,算是做一些早期的开机自启动任务,basic.target完成后进入第三个大目标 - 第三个大目标:『default.target运行级别』
default.target是一个软链接,链接到不同的target表示进入不同的『运行级别』,运行级别阶段的目的是为最终的登录做准备:- 如果是内核启动过程中(内核启动时调用了集成在initramfs中的systemd就处于这个过程),那么大目标是initrd.target,该target的目标是为后续虚根切换到实根做初始化准备,比如检查并挂载根文件系统,最终虚根切换实根,并进入真正的用户空间,也即完成了内核启动或内核已经成功登录
- 如果不是内核启动过程中,可能会选择不同的『运行级别』,通常是图形终端的graphical.target,或者多用户的运行级别multi-user.target,它们的目标都是完成系统启动,并准备让用户登录系统
所以,在内核启动阶段,要分析systemd的工作流程,沿着sysinit-->basic-->initrd-->kernel launched这条路线即可。
回到在内核启动阶段,systemd接管后续的启动操作,具体会做哪些事呢?在man bootup手册中给出了内核启动阶段中systemd的工作流程图。
如下图。
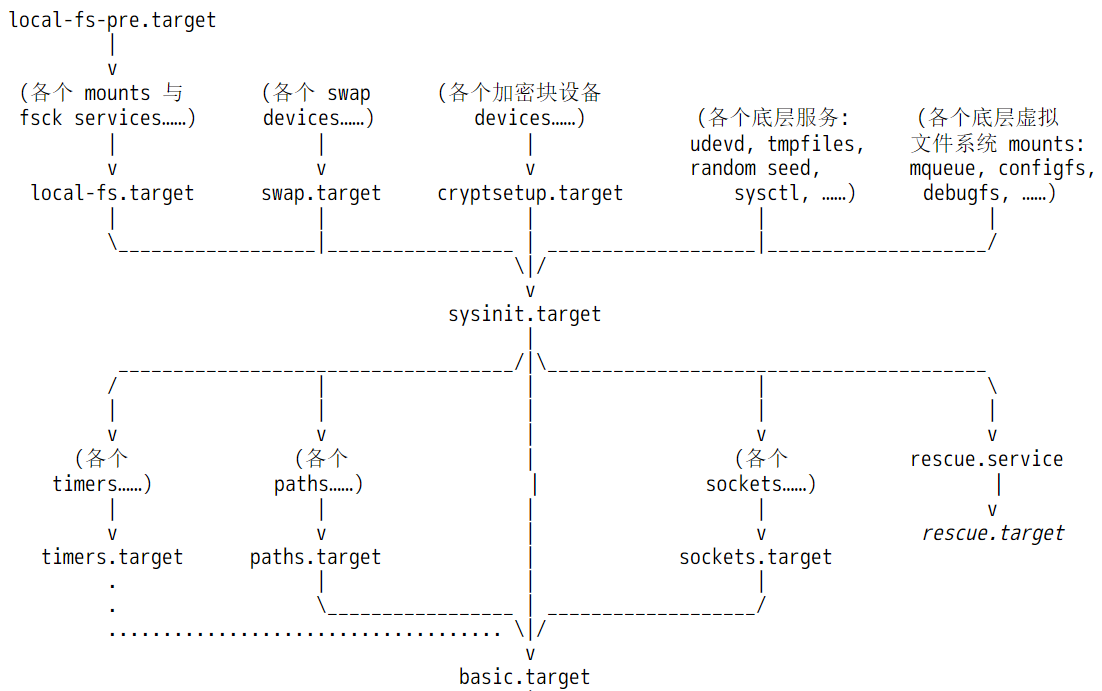
注意,图中所有涉及到的unit文件均来自initramfs镜像解压后的目录,也即虚根,而不是来自真实的根文件系统,因为现在还没有真实的根文件系统。例如<ramfs>/usr/lib/systemd/system/sysinit.target文件。
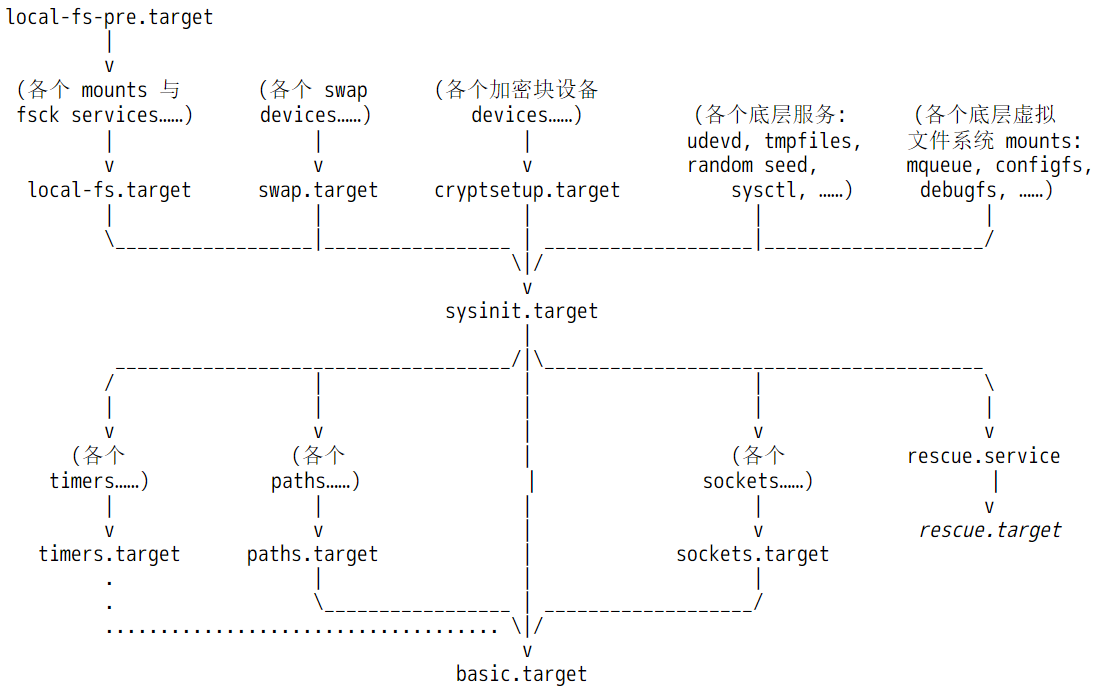
对于已经启动完成的正常系统来说,sysinit.target是用于做系统初始化的,basic.target则是系统初始化完成后执行的一些基本任务,比如启动所有定时器任务,开始监控指定文件等,算是系统启动过程中早期的开机自启动任务。
但是在内核启动阶段,sysinit.target和basic.target所代表的含义,显然与启动完成后这两个文件代表的含义有所不同。在内核启动阶段,sysinit.target中的sys指的是内核阶段的虚拟系统,basic则代表ramdisk决定要执行的基础任务。
换句话说,在内核启动阶段,systemd也将initramfs所启动的环境看作是一个操作系统,只不过是一个虚拟的操作系统。
当basic.target完成后,进入initrd.target,之所以是initrd.target,是因为initramfs中的default.target软链接指向的是initrd.target。
$ cd /tmp/hhh/usr/lib/systemd/system
$ ls -l default.target
...... default.target -> initrd.target
下图描述了initrd.target阶段的工作流程。
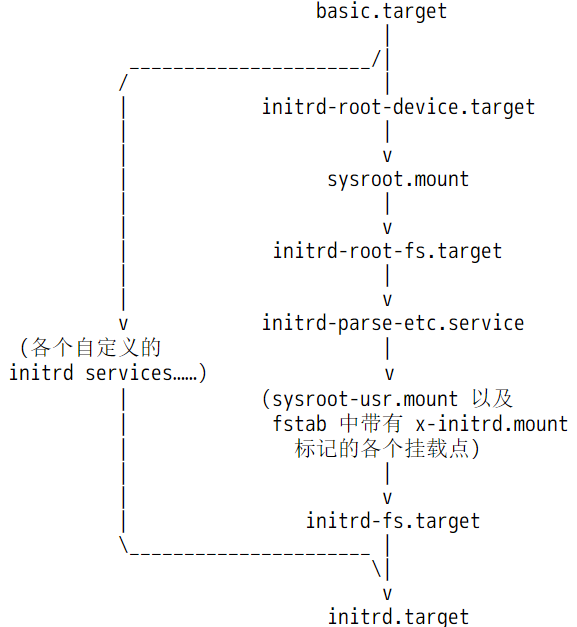
在initrd阶段,systemd为后续切换到真实的根文件系统做准备,比如检查根文件系统并将其挂载在<ramfs>/sysroot下,再比如从/etc/fstab中找出部分需要在这个阶段挂载的分区。如果一切没问题,将进入最后的阶段:从initramfs的虚根<ramfs>/切换到实根<ramfs>/sysroot。
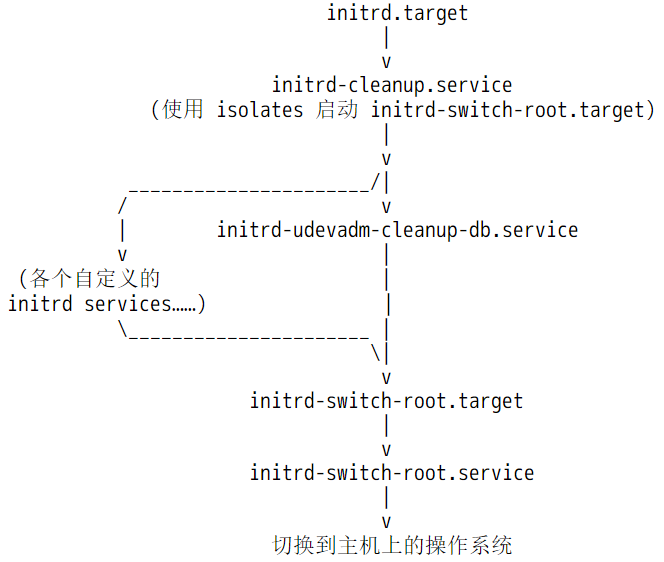
从此开始,<ramfs>/sysroot将代表真实的根文件系统,systemd也将从这个根文件系统调用init程序(systemd)替换当前的systemd进程(所以PID仍然为1)。从此内核引导阶段退出舞台,开始进入真正的用户空间,systemd进程也将在这个用户空间开始下一阶段的流程:sysinit->basic->default->login。
所以,总结一下内核启动阶段中systemd接管控制权后到用户登录中间的流程。如下图。虽然图中内核启动之后的阶段还未展开介绍,但我想大家应该能理解,即使不理解也没关系,稍后会展开。
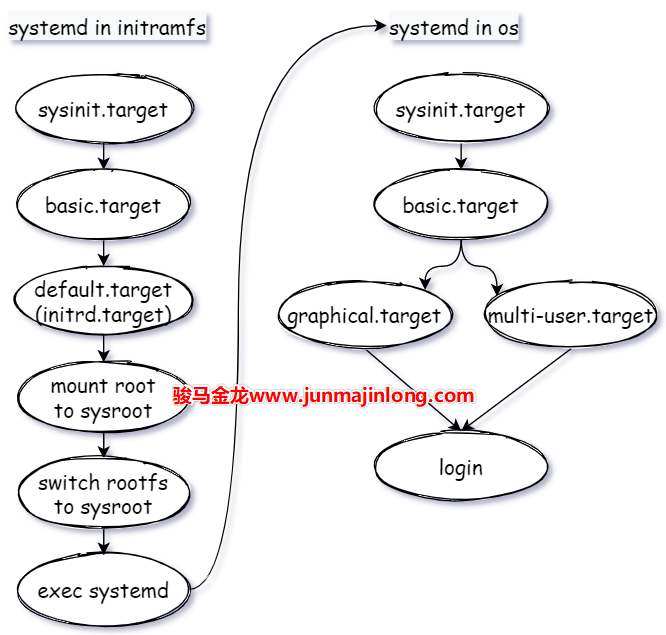
内核启动后,用户登录前
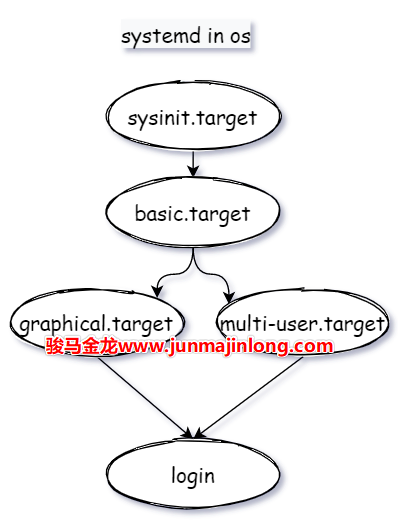
当systemd(这个是来自真实根文件系统的systemd进程)进入到用户空间后,systemd将执行下一轮工作流程,全局路线为:sysinit.target->basic.target->default.target->...->login。
其中default.target是一个软链接,一般指向graphical.target(图形界面)或multi-user.target(多用户模式),对应于SysV系统中的『运行级别』阶段。
需注意,在这里涉及到的所有unit文件都来自于真实的根文件系统,例如/usr/lib/systemd/system/sysinit.target。而内核启动阶段systemd工作路线中涉及到的unit文件都来自于initramfs构建的虚根,例如<ramfs>/usr/lib/systemd/system/sysinit.target,而且前文也提到过,在systemd眼中,initramfs构建的也是一个系统,只不过是虚拟系统,最终systemd会从这个虚拟系统中切换到真实的系统中,切换的内容主要包括两项:切换根分区,切换systemd进程自身。
在流程的每一个大阶段,和前面介绍的initramfs中的systemd是类似的。
basic.target完成后,将通过default.target决定进入哪一个『运行级别』。如果是进入graphical.target,那么会启动和图形终端相关的服务任务,如果是进入multi-user.target,那么:
$ cd /usr/lib/systemd/system/
$ ls -1 multi-user.target.wants
dbus.service
getty.target
systemd-ask-password-wall.path
systemd-logind.service
systemd-update-utmp-runlevel.service
systemd-user-sessions.service
其中几项需要注意:
- getty.target:启动虚拟终端实例(或容器终端实例)并初始化它们
- systemd-logind:负责管理用户登录操作
- systemd-user-sessions:控制系统是否允许登录
- systemd-update-utmp-runlevel:切换运行级别时在utmp和wtmp中记录切换信息
- systemd-ask-password-wall:负责查询用户密码
除了这几个multi-user.target所依赖的服务外,在/etc/systemd/system/multi-user.target.wants下也有需要启动的服务,这里的服务是用户定义的systemd类的开机自启动服务。
$ cd /etc/systemd/system
$ ls multi-user.target.wants
atd.service mcelog.service
auditd.service mdmonitor.service
chronyd.service NetworkManager.service
crond.service remote-fs.target
dnf-makecache.timer smartd.service
firewalld.service sshd.service
irqbalance.service sssd.service
kdump.service tuned.service
libstoragemgmt.service vdo.service
不仅如此,为了兼容早期sysV的rc.local开机自启动功能,systemd会检查/etc/rc.local是否具有可执行权限,如果具备,systemd会在此阶段自动执行rc.local中的命令。